Fundamentals of Custom Data Collection
Now, we know that the solution to your data collection needs could be creating custom datasets. Yet, collecting massive quantities of images and videos in-house could be a major challenge for most businesses. The next solution would be outsourcing the data creation to premium data collection vendors.
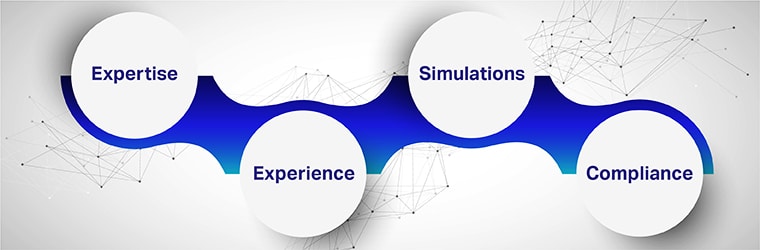
- Expertise: A data collection expert has the specialized tools, techniques, and equipment to create images and videos aligned with the project requirements.
- Experience: Data creation and annotation services experts should be able to gather data aligned with the project’s needs.
- Simulations: Since data collection depends on the frequency of events to be captured, targeting events that occur infrequently or in edge-case scenarios becomes a challenge.
To mitigate this, experienced companies simulate or artificially create training scenarios. These realistically simulated images help augment the dataset by constructing environments that are hard to find. - Compliance: When dataset collection is outsourced to reliable vendors, it is easier to ensure adherence to legal compliance and best practices.
Evaluating the quality of training datasets
While we have established the essentials of an ideal dataset, let’s now talk about evaluating the qualities of datasets.
Data Sufficiency: The greater the number of labeled instances your dataset has, the better the model.
There is no definite answer to the amount of data you might need for your project. However, the data quantity depends on the type and features present in your model. Start the data collection process slowly, and increase the quantity depending on the model complexity.
Data Variability: In addition to quantity, data variability is also important to consider when determining the dataset’s quality. Having several variables will negate data imbalance and aid in adding value to the algorithm.
Data Diversity: A deep learning model thrives on data diversity and dynamism. To ensure that the model is not biased or inconsistent, avoid over- or under-representing scenarios.
E.g., suppose a model is being trained to identify images of cars, and the model has been trained only on car images captured during daylight. In that case, it will yield inaccurate predictions when exposed during the night.
Data Reliability: Reliability and accuracy depend on several factors, such as human errors due to manual data labeling, duplication of data, and inaccurate data labeling attributes.
Use Cases of Computer Vision
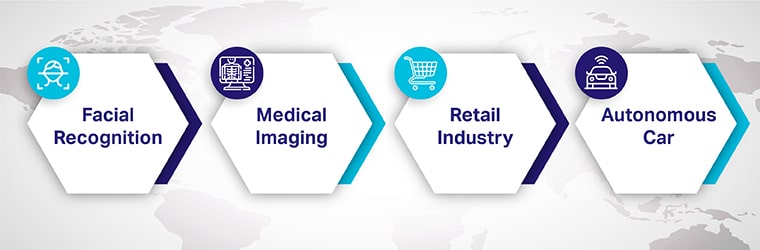
The core concepts of computer vision are integrated with machine learning to deliver everyday applications and advanced products. Some of the most common computer vision applications are
Facial Recognition: Facial recognition applications are a very common example of computer vision. Social media applications use facial recognition to identify and tag users in photos. The CV algorithm matches the face in images to its facial profile database.
Medical Imaging: Medical imaging data for computer vision plays a major role in healthcare delivery by automating critical tasks such as detecting tumors or cancerous skin lesions.
Retail & eCommerce Industry: The eCommerce industry is also finding computer vision technology useful. They use an algorithm that identifies clothing items and classifies them easily. This helps improve search and recommendations for a greater user experience.
Autonomous Cars: Computer vision is paving the way for advanced autonomous vehicles by enhancing their capabilities to understand their environment. The CV software is fed with thousands of video captures from different angles. They are processed and analyzed to understand road signs and detect other vehicles, pedestrians, objects, and other edge-case scenarios.
So, what is the first step in developing a high-end, efficient, and reliable computer vision solution trained on ML models?
Seeking out expert data collection and annotation experts who can provide the highest quality AI training data for computer vision with expert human-in-the-loop annotators to ensure accuracy.
With a large, diverse, high-quality dataset, you can focus on training, tuning, designing, and deploying the next-big computer vision solution. And ideally, your data service partner should be Shaip, the industry leader in providing end-to-end tested computer vision services for developing real-world AI applications.
[Also Read: AI Training Data Starter Guide: Definition, Example, Datasets]