
Imagine conversing with your smartphone, listening to your favorite articles read aloud while driving, or learning a new language with perfect pronunciation—all without human intervention. This is the magic of Text-to-Speech (TTS) technology.
Companies are also heavily investing in TTS, especially after the AI boom. The TTS market was valued at $3.2 billion in 2023 and is expected to reach $7 billion by 2030, growing at a CAGR of 12%.
What started as a simple feature has now evolved into something entirely different—Conversational AI. Text-to-speech is the same tech that is now powering virtual assistants, customer service bots, etc. So in this guide, we will walk you through everything you need to know about text-to-speech.
But What is Text-to-Speech and How it Works?
At its core, Text-to-Speech (TTS) technology is all about giving a voice to the text. In simple terms, it will take the text as an input which can be in any form including a sentence, a paragraph, or an entire document—and transform it into spoken language. For the most part, the generated voice is close to human voice but it might differ from product to product.
One good example is Google Assistant’s voice sounds robotic but on the other hand, modern AI tools like hume.ai are very close to human voice.
Like any other technology, TTS technology also became complex with time as multiple AI and ML algorithms were added to enhance its capability. But for your convenience, we have divided the workings of text-to-speech into three parts.
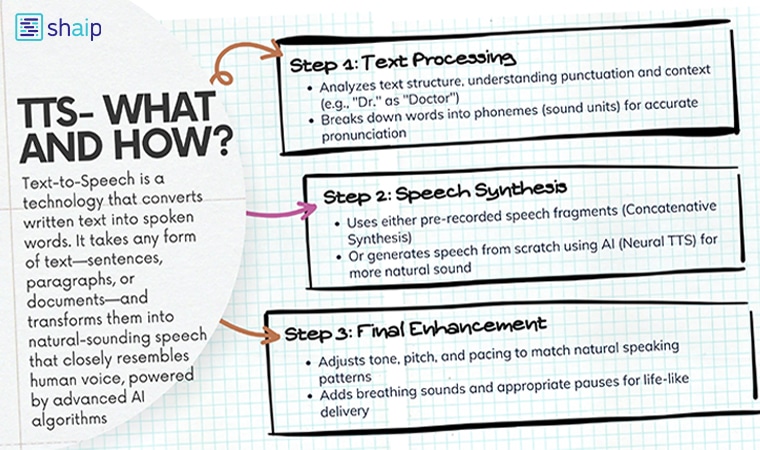
Step 1: Text Processing
This is the first step, where the TTS system prepares the text for speech. Here’s what happens:
- Analyzing the text: The system will first scan the text to understand its structure which includes everything ranging from punctuation, abbreviations, and even numbers. By doing so, the system can have a better understanding of the context. One good example is that “Dr.” is recognized as “Doctor,” not “Drive.”
- Breaking Down Words: Later on, words are split into their phonetic components, known as phonemes. This is one of the crucial steps to ensure correct pronunciation. These are the smallest units of sound in speech. One good example of breaking down words into phonemes is the word “cat” which has three phonemes: /k/, /æ/, and /t/.
- Handling Context: In this step, the system will learn the context of the text to decide how to pronounce words. For example, the word “lead” might be pronounced differently in “lead a team” versus “lead pipe.”
Step 2: Speech Synthesis
Once the text is processed, the next step is to convert it into actual speech. This is done using one of two main methods:
- Concatenative Synthesis: This is a traditional method that has been used for a very long. The process is quite simple where you use pre-recorded fragments of human speech and stitch them together to form the sentence.
For example, to say “Hello, world,” the system might pull the pre-recorded sound for “Hello,” and “world,” and then stitch them to form a sentence. While it is effective, the big downside is that the generated audio might sound choppy or robotic, especially with complex sentences. - Neural TTS (Modern Approach): Unlike the previous method where the system would stitch pre-recorded clips, Neural TTS is a modern method and uses artificial intelligence and deep learning to generate speech from scratch.
For example, to say “Hello, world,” the neural network technique will generate the entire sentence in a close to natural tone which will also be emotional and inflectious. This is the reason why you will find night and day differences between old and new TTS software in terms of speech quality.
This approach creates highly realistic, expressive, and human-like speech, making it the preferred choice for many advanced TTS systems today.
Step 3: Adding the Finishing Touches
In the final step, the TTS system adds the final touch to enhance the output:
- Tone and Pitch: It is done to help express emotions or emphasis. For example, excitement is expressed with a higher pitch, while seriousness is reflected in a lower tone.
- Pacing: It will Adjust the speed of the speech to match the natural speaking pattern based on the context of the text.
- Breathing and Pauses: This is the most important in my opinion where these advanced systems simulate natural breathing sounds and pauses using AI and ML, making the output more life-like. The best example is how NotebookLM generates audio from text in conversational form with breathing and pauses which mimics how exactly the human speaks.
What is The Role of AI in TTS

We believe that AI has revolutionized the TTS technology and has enabled us important features that we use daily like the ability to produce realistic and natural-sounding speech. Along with these features, the accuracy has also improved to a large extent.
Here are the most significant contributions of AI to the TTS technology:
- Neural TTS for Human-Like Voices: By far, this is the most important contribution of AI to TTS. With AI, now we are witnessing Neural TTS which not only mimics human-like speech but also has emotions, pauses, and depth which is not possible without AI. Unlike traditional methods, it creates fluid, lifelike voices without relying on pre-recorded segments.
- Emotional Touch: With AI, text-to-speech systems can generate audio that has emotions. This is specifically useful when you are talking to a chatbot and it has an emphatical voice which is beneficial for both companies and users. This is the reason why more and more TTS systems are now being used in storytelling, therapy, and virtual assistants.
- Customizable AI Voices: Since the integration of AI with TTS, you can create personalized voices for personal and professional use as the tone can easily be changed as per the needs. For example, companies can build empathic models with tones that match this use case, but on the other hand, if an individual wants to build something for fun, can build a model that sounds like JARVIS, a movie-inspired tool.
- Multilingual and Accent Support: With AI, TTS systems can easily understand and respond in multiple languages. This way, companies can ensure inclusivity and accessibility for global audiences. But the best part is it also adapts to regional nuances which eventually improves relatability.
- Integration with Conversational AI: TTS when integrated with AI has become an integral part of the modern AI assistants like Alexa and Siri. It ensures that these assistants deliver responses that are conversational, engaging, and contextually appropriate.
Challenges That Companies Face to Develop TTS
Despite modern tech, there are multiple challenges that companies face to develop and utilize the true potential of TTS. Here are some of the key problems:
- Data Availability and Quality: The outcome of the TTS system heavily relies on the quality of datasets and companies need large amounts of quality data which is difficult to find and costly to purchase.
- Achieving Naturalness and Expressiveness: This is one of the most crucial problems that companies face and that is—achieving naturalness and expressiveness. While modern AI and ML algorithms have solved this problem to a large extent, these systems often fall short in replicating context-sensitive expressions like sarcasm or excitement.
- High Computational Costs: If you want to develop advanced TTS models that are powered by AI, similar to Tacotron or WaveNet, get ready to spend an excruciating amount of money on computational power. These advanced TTS systems demand modern GPUs for inferencing and training which might turn out to be a huge problem for small organizations.
- Multilingual and Regional Adaptation: Building a TTS system that alone understands multiple languages and accents is a huge problem. This is the reason why companies often develop multiple TTS for multiple languages and merge them to solve this problem. Even such a solution might not be able to solve this problem 100%.
How can Shaip Redefine Text-to-Speech for You?
Whether you are developing virtual assistants, interactive voice response systems, or any AI-driven voice applications, Shaip is here to hold your hand. We have expertise in speech data collection and processing so that your TTS systems can not only be made accurate but also sound natural and relevant.
Here’s how Shaip can elevate your TTS projects:
- Custom TTS Data Solutions: Shaip can provide you with tailored TTS datasets that meet the specific needs of your project. From studio-quality recordings to real-world scenarios, the data is meticulously curated to enhance the clarity and fluency of the generated speech.
- High-quality speech Data Catalog: At Shaip, you can have access to a very large speech data catalog and get pre-labeled voice datasets from the vast repository. Ethically sourced datasets with metadata ensure you get the best quality training data for your AI models.
- Expert Evaluation & Support: We go one step beyond providing data. We also offer evaluation services that ensure that TTS meets the high standards of natural speech and accuracy.
By collaborating with Shaip, you get access to world-class speech data solutions which will significantly improve the outcome of your next TTS system. Whether you are looking for custom datasets or ready-made solutions, you ask and we’ll make it work for you.









