
Large Multimodal Models (LMMs) are a revolution in artificial intelligence (AI). Unlike traditional AI models that operate within a single data environment such as text, images, or audio, LMMs are capable of creating and processing multiple modalities simultaneously.
Hence the generation of outputs with context-aware multimedia information. The purpose of this article is to unravel what LMMs are, how they get to be different from LLMs, and where they can be applied, grounded by technologies that make this possible.
Large Multimodal Models Explained
LMMs are AI systems that can process and interpret multiple types of data modalities. A modality is a term used to represent any data structure that can be input into a system. In short, traditional AI models work on only one modality (for example, text-based language models or image recognition systems) at a time; LMMs break this barrier by bringing information from different sources into a common framework for analysis.
For example—LLMs can be one of the AI systems that may read a news article (text), analyze the accompanying photographs (images), and correlate it with related video clips to render an extensive summary.
It can read an image of a menu in a foreign language, do a textual translation of it, and make dietary recommendations depending on the content. Such modality integration opens a cosmic door for LMMs to do those things that were previously difficult for unimodal AI systems.
How LMMs Work
The methods that enable LMMs to handle multimodal data effectively and optimally can be grouped into architectures and training techniques. Here is how they work:
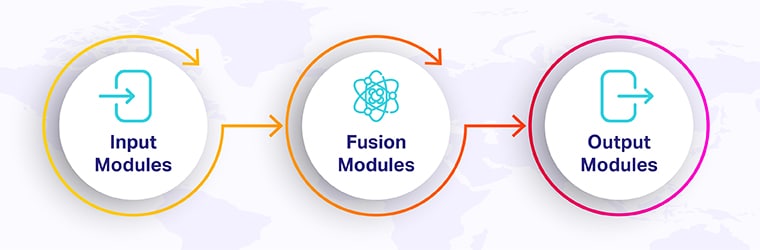
- Input Modules: Emotional and distinct neural networks manage every modality. In this case, text would be a natural language processing by a natural language processing model (NLP); an image would be a convolutional neural network (CNN); and audio would be a trained RNN or transformer.
- Fusion Modules: This would take the outputs of the input modules and combine them into a single representation.
- Output Modules: Here the merged representation gives way to generating a result in the form of a prediction, decision, or response. For example—generating captions about an image-answering query about a video-translating spoken allow into actions.
LMMs vs. LLMs: Key Differences
| Feature | Large Language Models (LLMs) | Large Multimodal Models (LMMs) |
|---|---|---|
| Data Modality | Text-only | Text, images, audio, video |
| Capabilities | Language understanding and generation | Cross-modal understanding and generation |
| Applications | Writing articles, summarizing documents | Image captioning, video analysis, multimodal Q&A |
| Training Data | Text corpora | Text + images + audio + video |
| Examples | GPT-4 (text-only mode) | GPT-4 Vision, Google Gemini |
Applications for Large Multimodal Models
As the LMMs can compute multiple types of data at the same time, the degrees of their applications and spread are very high in different sectors.






