
If you’re building voice interfaces, transcription, or multimodal agents, your model’s ceiling is set by your data. In speech recognition (ASR), that means collecting diverse, well-labeled audio that mirrors real-world users, devices, and environments—and evaluating it with discipline.
This guide shows you exactly how to plan, collect, curate, and evaluate speech training data so you can ship reliable products faster.
What Counts as “Speech Recognition Data”?
At minimum: audio + text. Practically, high-performing systems also need rich metadata (speaker demographics, locale, device, acoustic conditions), annotation artifacts (timestamps, diarization, non-lexical events like laughter), and evaluation splits with robust coverage.
Pro tip: When you say “dataset,” specify the task (dictation vs. commands vs. conversational ASR), domain (support calls, healthcare notes, in-car commands), and constraints (latency, on-device vs. cloud). It changes everything from sampling rate to annotation schema.
The Speech Data Spectrum (Pick What Matches Your Use Case)
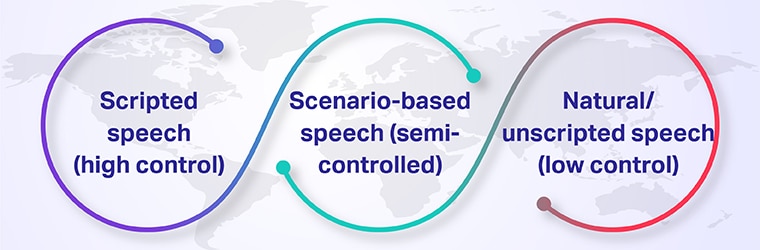
1. Scripted speech (high control)
Speakers read prompts verbatim. Great for command & control, wake words, or phonetic coverage. Fast to scale; less natural variation.
2. Scenario-based speech (semi-controlled)
Speakers act out prompts within a scenario (“ask a clinic for a glaucoma appointment”). You get varied phrasing while staying on task—ideal for domain language coverage.
3. Natural/unscripted speech (low control)
Real conversations or free monologues. Necessary for multi-speaker, long-form, or noisy use cases. Harder to clean, but crucial for robustness. The original article introduced this spectrum; here we emphasize matching spectrum to product to avoid over- or under-fitting.
Plan Your Dataset Like a Product
Define success and constraints up front
- Primary metric: WER (Word Error Rate) for most languages; CER (Character Error Rate) for languages without clear word boundaries.
- Latency & footprint: Will you run on-device? That impacts sampling rate, model, and compression.
- Privacy & compliance: If you touch PHI/PII (e.g., healthcare), ensure consent, de-identification, and auditability.
Map real usage into data specs
- Locales & accents: e.g., en-US, en-IN, en-GB; balance urban/rural and multilingual code-switching.
- Environments: office, street, car, kitchen; SNR targets; reverb vs. close-talk mics.
- Devices: smart speakers, mobiles (Android/iOS), headsets, car kits, landlines.
- Content policies: profanity, sensitive topics, accessibility cues (stutter, dysarthria) where appropriate and permitted.
How Much Data Do You Need?
There’s no single number, but coverage beats raw hours. Prioritize breadth of speakers, devices, and acoustics over ultra-long takes from a few contributors. For command-and-control, thousands of utterances across hundreds of speakers often beat fewer, longer recordings. For conversational ASR, invest in hours × diversity plus careful annotation.
Current landscape: Open-source models (e.g., Whisper) trained on hundreds of thousands of hours set a strong baseline; domain, accent, and noise adaptation with your data is still what moves production metrics.
Collection: Step-by-Step Workflow
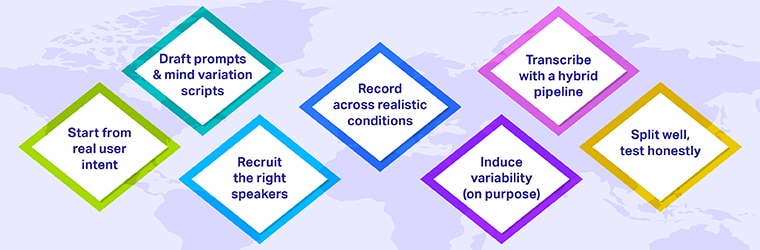
1. Start from real user intent
Mine search logs, support tickets, IVR transcripts, chat logs, and product analytics to draft prompts and scenarios. You’ll cover long-tail intents you’d otherwise miss.
2. Draft prompts & scripts with variation in mind
- Write minimal pairs (“turn on the living room light” vs. “switch on…”).
- Seed disfluencies (“uh, can you…”) and code-switching if relevant.
- Cap read sessions to ~15 minutes to avoid fatigue; insert 2–3 second gaps between lines for clean segmentation (consistent with your original guidance).
3. Recruit the right speakers
Target demographic diversity aligned to market and fairness goals. Document eligibility, quotas, and consent. Compensate fairly.
4. Record across realistic conditions
Collect a matrix: speakers × devices × environments.
For example:
- Devices: iPhone mid-tier, Android low-tier, smart speaker far-field mic.
- Environments: quiet room (near-field), kitchen (appliances), car (highway), street (traffic).
- Formats: 16 kHz / 16-bit PCM is common for ASR; consider higher rates if you’ll downsample.
5. Induce variability (on purpose)
Encourage natural pace, self-corrections, and interruptions. For scenario-based and natural data, don’t over-coach; you want the messiness your customers produce.
6. Transcribe with a hybrid pipeline
- Auto-transcribe with a strong baseline model (e.g., Whisper or your in-house).
- Human QA for corrections, diarization, and events (laughter, filler words).
- Consistency checks: spelling dictionaries, domain lexicons, punctuation policy.
7. Split well; test honestly
- Train/Dev/Test with speaker and scenario disjointness (avoid leakage).
- Keep a real-world blind set that mirrors production noise and devices; don’t touch it during iteration.
Annotation: Make Labels Your Moat
Define a clear schema
- Lexical rules: numbers (“twenty five” vs. “25”), acronyms, punctuation.
- Events: [laughter], [crosstalk], [inaudible: 00:03.2–00:03.7].
- Diarization: Speaker A/B labels or tracked IDs where permitted.
- Timestamps: word- or phrase-level if you support search, subtitles, or alignment.
Train annotators; measure them
Use gold tasks and inter-annotator agreement (IAA). Track precision/recall on critical tokens (product names, meds) and turnaround times. Multi-pass QA (peer review → lead review) pays off later in model eval stability.
Quality Management: Don’t Ship Your Data Lake
- Automated screens: clipping, clipping ratio, SNR bounds, long silences, codec mismatches.
- Human audits: random samples by environment and device; spot check diarization and punctuation.
- Versioning: Treat datasets like code—semver, changelogs, and immutable test sets.
Evaluating Your ASR: Beyond a Single WER
Measure WER overall and by slice:
- By environment: quiet vs. car vs. street
- By device: low-tier Android vs. iPhone
- By accent/locale: en-IN vs. en-US
- By domain terms: product names, meds, addresses
Track latency, partials behavior, and endpointing if you power real-time UX. For model monitoring, research on WER estimation and error detection can help prioritize human review without transcribing everything.

Build vs. Buy (or Both): Data Sources You Can Combine

1. Off-the-shelf catalogs
Useful for bootstrapping and pretraining, especially to cover languages or speaker diversity quickly.
2. Custom data collection
When domain, acoustic, or locale requirements are specific, custom is how you hit on-target WER. You control prompts, quotas, devices, and QA.
3. Open data (carefully)
Great for experimentation; ensure license compatibility, PII safety, and awareness of distribution shift relative to your users.
Security, Privacy, and Compliance
- Explicit consent and transparent contributor terms
- De-identification/anonymization where appropriate
- Geo-fenced storage and access controls
- Audit trails for regulators or enterprise customers
Real-World Applications (Updated)
- Voice search & discovery: Growing user base; adoption varies by market and use case.
- Smart home & devices: Next-gen assistants support more conversational, multi-step requests—raising the bar on training data quality for far-field, noisy rooms.
- Customer support: Short-turn, domain-heavy ASR with diarization and agent assist.
- Healthcare dictation: Structured vocabularies, abbreviations, and strict privacy controls.
- In-car voice: Far-field microphones, motion noise, and safety-critical latency.
Mini Case Study: Multilingual Command Data at Scale
A global OEM needed utterance data (3–30 seconds) across Tier-1 and Tier-2 languages to power on-device commands. The team:
- Designed prompts covering wake words, navigation, media, and settings
- Recruited speakers per locale with device quotas
- Captured audio across quiet rooms and far-field environments
- Delivered JSON metadata (device, SNR, locale, gender/age bucket) plus verified transcripts
Result: A production-ready dataset enabling rapid model iteration and measurable WER reduction on in-domain commands.
Common Pitfalls (and the Fix)
- Too many hours, not enough coverage: Set speaker/device/environment quotas.
- Leaky eval: Enforce speaker-disjoint splits and a truly blind test.
- Annotation drift: Run ongoing QA and refresh guidelines with real examples.
- Ignoring edge markets: Add targeted data for code-switching, regional accents, and low-resource locales.
- Latency surprises: Profile models with your audio on target devices early.
When to Use Off-the-Shelf vs. Custom Data
Use off-the-shelf to bootstrap or to broaden language coverage quickly; switch to custom as soon as WER plateaus on your domain. Many teams blend: pretrain/fine-tune on catalog hours, then adapt with bespoke data that mirrors your production funnel.
Checklist: Ready to Collect?
- Use-case, success metrics, constraints defined
- Locales, devices, environments, quotas finalized
- Consent + privacy policies documented
- Prompt packs (scripted + scenario) prepared
- Annotation guidelines + QA stages approved
- Train/dev/test split rules (speaker- and scenario-disjoint)
- Monitoring plan for post-launch drift
Key Takeaways
- Coverage beats hours. Balance speakers, devices, and environments before chasing more minutes.
- Labeling quality compounds. Clear schema + multi-stage QA outperform single-pass edits.
- Evaluate by slice. Track WER by accent, device, and noise; that’s where product risk hides.
- Blend data sources. Bootstrapping with catalogs + custom adaptation is often fastest to value.
- Privacy is product. Put consent, de-ID, and auditability in from day one.
How Shaip Can Help You
Need bespoke speech data? Shaip provides custom collection, annotation, and transcription—and offers ready-to-use datasets with off-the-shelf audio/transcripts in 150+ languages/variants, carefully balanced by speakers, devices, and environments.









