
It is estimated that on average adult makes decisions on life and everyday things based on past learning. These, in turn, come from life experiences shaped by situations and people. In the literal sense, situations, instances, and people are nothing but data that gets fed into our minds. As we accumulate years of data in the form of experience, the human mind tends to make seamless decisions.
What does this convey? That data is inevitable in learning.

Similar to how a child needs a label called an alphabet to understand the letters A, B, C, D a machine also needs to understand the data it is receiving.
That’s exactly what Artificial Intelligence (AI) training is all about. A machine is no different than a child who has yet to learn things from what they are about to be taught. The machine does not know to differentiate between a cat and a dog or a bus and a car because they haven’t yet experienced those items or been taught what they look like.
So, for someone building a self-driving car, the primary function that needs to be added is the system’s ability to understand all the everyday elements the car may encounter, so the vehicle can identify them and make appropriate driving decisions. This is where AI training data comes into play.
Today, artificial intelligence modules offer us many conveniences in the form of recommendation engines, navigation, automation, and more. All of that happens due to AI data training that was used to train the algorithms while they were built.
AI training data is a fundamental process in building machine learning and AI algorithms. If you are developing an app that is based on these tech concepts, you need to train your systems to understand data elements for optimized processing. Without training, your AI model will be inefficient, flawed and potentially pointless.
What is AI Training Data?

It’s simple – data which is used to train a machine learning model is called training data. The anatomy of a training dataset involves labeled or annotated attributes, which allow models to detect and learn from patterns. Annotated data is critical in data training as it enables models to distinguish, compare, and correlate probabilities in the learning phase. Quality training data involves human-approved datasets, where data has gone through rigorous quality checks to ensure annotations are precise and correct. The clearer the annotation, the higher the data quality.
Why Is AI Training Data Important?
The quality of AI training data directly translates to the quality of output of machine learning models. This correlation becomes more critical in sectors such as healthcare and automotive, where human lives are directly at stake. Besides, AI training data also influences the bias quotient of outputs.
For instance, a model that has been trained with just one class of sample set, say, from the same demographics or human persona, it may often lead to the machine assuming there exists no different types of probabilities. This gives rise to unfairness in output, which could eventually fetch companies legal and reputational consequences. To mitigate this, sourcing quality data and training models on this is highly recommended.
Example: How Self-Driving Cars Use AI Training Data to Navigate Safely
Autonomous cars use massive amounts of data from sensors like cameras, RADAR, and LIDAR. This data is useless if the car’s system can’t process it. For example, the car needs to recognize pedestrians, animals, and potholes to avoid accidents. It must be trained to understand these elements and make safe driving decisions.
Additionally, the car should understand spoken commands using Natural Language Processing (NLP). For instance, if asked to find nearby gas stations, it should interpret and respond accurately.
AI training is crucial not just for cars but for any AI system, like Netflix recommendations, which also rely on similar data processing to offer personalized suggestions.

How Much Data Is Required To Train ML Models?
They say there is no end to learning and this phrase is ideal in the AI training data spectrum. The more the data, the better the results. However, a response as vague as this is not enough to convince anyone who is looking to launch an AI-powered app. But the reality is that there is no general rule of thumb, a formula, an index or a measurement of the exact volume of data one needs to train their AI data sets.

A machine learning expert would comically reveal that a separate algorithm or module has to be built to deduce the volume of data required for a project. That’s sadly the reality as well.
Now, there is a reason why it is extremely difficult to put a cap on the volume of data required for AI training. This is because of the complexities involved in the training process itself. An AI module comprises several layers of interconnected and overlapping fragments that influence and complement each other’s processes.
For instance, let’s consider you are developing a simple app to recognize a coconut tree. From the outlook, it sounds rather simple, right? From an AI perspective, however, it is much more complex.
At the very start, the machine is empty. It does not know what a tree is in the first place let alone a tall, region-specific, tropical fruit-bearing tree. For that, the model needs to be trained on what a tree is, how to differentiate from other tall and slender objects that may appear in frame like streetlights or electric poles and then move on to teach it the nuances of a coconut tree. Once the machine learning module has learnt what a coconut tree is, one could safely assume it knows how to recognize one.
But only when you feed an image of a banyan tree, you would realize that the system has misidentified a banyan tree for a coconut tree. For a system, anything that is tall with clustered foliage is a coconut tree. To eliminate this, the system needs to now understand every single tree that is not a coconut tree to identify precisely. If this is the process for a simple unidirectional app with just one outcome, we can only imagine the complexities involved in apps that are developed for healthcare, finance and more.

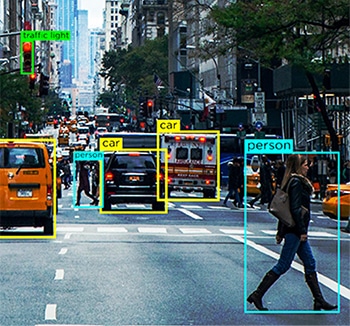


How do you improve Data Quality?
The quality of data is directly proportional to the quality of output. That’s why highly accurate models require high quality datasets for training. However, there is a catch. For a concept that is reliant on precision and accuracy, the concept of quality is often rather vague.
High-quality data sounds strong and credible but what does it actually mean?
What is quality in the first place?
Well, like the very data we feed into our systems, quality has a lot of factors and parameters associated with it as well. If you reach out to AI experts or machine learning veterans, they might share any permutation of high-quality data is anything that is –

- Uniform – data that is sourced from one particular source or uniformity in datasets that are sourced from multiple sources
- Comprehensive – data that covers all possible scenarios your system is intended to work on
- Consistent – every single byte of data is similar in nature
- Relevant – the data you source and feed is similar to your requirements and expected outcomes and
- Diverse – you have a combination of all types of data such as audio, video, image, text and more
Now that we understand what quality in data quality means, let’s quickly look at the different ways we could ensure quality data collection and generation.
What affects training data quality?
There are three main factors that can help you predict the level of quality you desire for your AI/ML Models. The 3 key factors are People, Process and Platform that can make or break your AI Project.
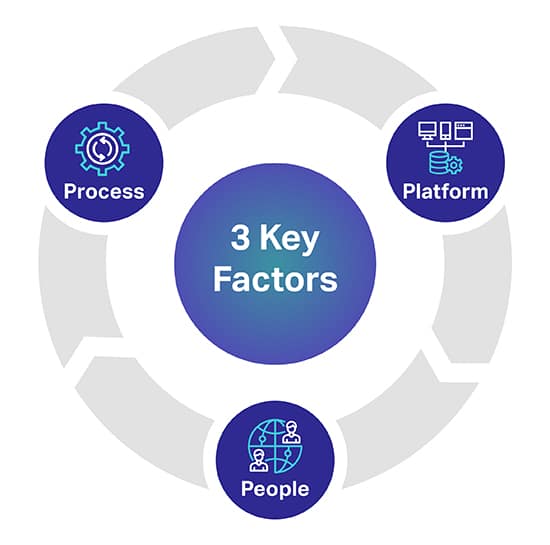
Platform: A complete human-in-the-loop proprietary platform is required to source, transcribe and annotate diverse datasets for successfully deploying the most demanding AI and ML initiatives. The platform is also responsible to manage workers, and maximize quality and throughput
People: To make AI think smarter takes people who are some of the smartest minds in the industry. In order to scale you need thousands of these professionals throughout the world to transcriber, label, and annotate all data types.
Process: Delivering gold-standard data that is consistent, complete, and accurate is complex work. But it’s what you will always need to deliver, so as to adhere to the highest quality standards as well as stringent and proven quality controls and checkpoints.
Where do you source AI Training Data from?
Unlike our previous section, we have a very precise insight here. For those of you looking to source data
or if you are in the process of video collection, image collection, text collection and more, there are three
primary avenues you can source your data from.
Let’s explore them individually.
Free Sources
Free sources are avenues that are involuntary repositories of massive volumes of data. It is data that is simply lying there on the surface for free. Some of the free resources include –

- Google datasets, where over 250 million sets of data were released in 2020
- Forums like Reddit, Quora and more, which are resourceful sources for data. Besides, data science and AI communities in these forums could also help you with particular data sets when reached out.
- Kaggle is another free source where you can find machine learning resources apart from free data sets.
- We have also listed free open datasets to get you started with training your AI models
While these avenues are free, what you would end up spending are time and effort. Data from free sources is all over the place and you have to put in hours of work into sourcing, cleaning and tailoring it to suit your needs.
One of the other important pointers to remember is that some of the data from free sources cannot be used for commercial purposes as well. It requires data licencing.
Open Datasets – To use or not to use?

For instance, there is the Amazon product reviews dataset that features over 142 million user reviews from 1996 to 2014. For images, you have an excellent resource like Google Open Images, where you can source datasets from over 9 million pictures. Google also has a wing called Machine Perception that offers close to 2 million audio clips that are of ten seconds duration.
Despite the availability of these resources (and others), the important factor that is often overlooked is the conditions that come with their usage. They are public for sure but there is a thin line between breach and fair use. Each resource comes with its own condition and if you are exploring these options, we suggest caution. This is because in the pretext of preferring free avenues, you could end up incurring lawsuits and allied expenses.
The True Costs of AI Training Data
Only the money that you spend to procure the data or generate data in-house is not what you should consider. We must consider linear elements like time and efforts spent in developing AI systems and cost from a transactional perspective. fails to compliment the other.
Time Spent on Sourcing and Annotating Data
Factors like geography, market demographics, and competition within your niche hinder the availability of relevant datasets. The time spent manually searching for data is time-wasting in training your AI system. Once you manage to source your data, you will further delay training by spending time annotating the data so your machine can understand what it is being fed.
The Price of Collecting and Annotating Data
Overhead expenses (In-house data collectors, Annotators, Maintaining equipment, Tech infrastructure, Subscriptions to SaaS tools, Development of proprietary applications) are required to be calculate while sourcing AI data
The Cost of Bad Data
Bad data can cost your company team morale, your competitive edge, and other tangible consequences that go unnoticed. We define bad data as any dataset that is unclean, raw, irrelevant, outdated, inaccurate, or full of spelling errors. Bad data can spoil your AI model by introducing bias and corrupting your algorithms with skewed results.
Management Expenses
All costs involving the administration of your organization or enterprise, tangibles, and intangibles constitute management expenses which are quite often the most expensive.

How To Choose The Right AI Training Data Company And How Shaip Can Help You?
Choosing the right AI training data provider is a critical aspect in ensuring your AI model performs well in the market. Their role, understanding of your project, and contribution can be game-changing for your business. Some of the factors to consider in this process include:
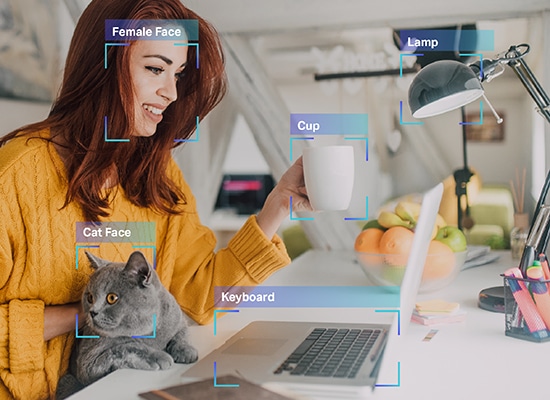
- the understanding of the domain your AI model is to be built
- any similar projects they have previously worked on
- would they provide sample training data or agree to a pilot collaboration
- how do they handle data requirements at scale
- what are their quality assurance protocols
- are they open to being agile in operations
- how do they source ethical training datasets and more
Or, you can skip all this and directly get in touch with us at Shaip. We are one of the leading providers of premium-quality ethically sourced AI training data. Having been in the industry for years, we understand the nuances involved in sourcing datasets. Our dedicated project managers, team of quality assurance professionals, and AI experts will ensure a seamless and a transparent collaboration for your enterprise visions. Get in touch with us to further discuss the scope today.