Large Language Models (LLMs) such as GPT-4 and Llama 3 have affected the AI landscape and performed wonders ranging from customer service to content generation. However, adapting these models for specific needs usually means choosing between two powerful techniques: Retrieval-Augmented Generation (RAG) and fine-tuning.
While both these approaches enhance LLMs, they are articulate towards different aims and are successful in different situations. Let us study these two methods in detail advantages and disadvantages and how one may select one for their need.
Retrieval-Augmented Generation (RAG)- What is It?

RAG is an approach that synergizes the generative capabilities of LLMs with retrieval for contextually precise answers. Rather than only using the knowledge it tested on, RAG fetches relevant information via external databases or knowledge repositories to infuse the information in the answer-generating process.
How RAG Works
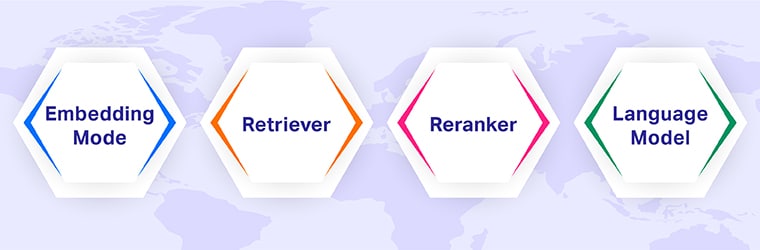
- Embedding Model: Embeds both the documents and the queries into the vector space to make a comparison more efficient.
- Retriever: Looks into a knowledge base via embeddings to grab relevant documents.
- Reranker: Scores the retrieved documents according to how relevant they are.
- Language model: Merges retrieved data with a user’s queries into one response.
Advantages of RAG
- Dynamic Knowledge Upgrades: Provides an efficient hit of information with the update processes greatly reduced through the process of model retraining.
- Reduction of Hallucination: By properly grounding responses on external knowledge, RAG minimizes factual inaccuracies.
- Scalability: Can be easily imbedded into large, diverse datasets thereby allowing its options for useful open-ended and dynamic tasks, such as customer agents and news summarization.
Limitations of RAG
- Latency: The very attentiveness in information extraction, delays the output time which results in higher latency and makes it irrelevant for real-time work environments.
- Quality of Knowledge Base: Dependability in the retrieval and relevance of external knowledge becomes important as answers depend solely on these sources.

Fine-Tuning- What Is It?

Fine-tuning is a process of retraining a pre-trained LLM on a specific domain dataset in the preparation of specialized task execution, allowing the model to fully understand nuanced patterns existing within the limit of a certain context.
How Fine-Tuning Works

- Data Preparation: Task-specific datasets will have to be cleaned and set aside into training, validation, and testing subsets.
- Model Training: The LLM will have to train on this dataset with methods that include backpropagation and gradient descent.
- Contents of Hyperparameter Tuning: Provides fine-tuning on a few of the critical hyperparameter contents such as batch size, and learning rate, among others.
Advantages of Fine-Tuning
- Customization: Allows authorities over the model’s actions, tone, and style in outputs.
- Efficiency in Inference: When an LLM has been fine-tuned, it produces quick responses without any external retrieval process.
- Specialized Skillset: Best suited for applications that require quality and accuracy across well-understood domains, such as freezing, medical evaluations, and contract analysis.
Cons of Fine-Tuning
- Resource-Intensive: Requires both great computing power and adequately high-quality labeled data.
- Catastrophic Forgetting: Fine-tuning tends to overwrite previously acquired generic knowledge and thereby limit its potential to cater to new tasks.
- Static Knowledge Base: Once training has been completed, its knowledge remains intact unless retaught on additional new data.
Key Differences Between RAG and Fine-Tuning
| Feature | Retrieval-Augmented Generation (RAG) | Fine-Tuning |
|---|---|---|
| Knowledge Source | External databases (dynamic) | Internalized during training (static) |
| Adaptability to New Data | High; updates via external sources | Low; requires retraining |
| Latency | Higher due to retrieval steps | Low; direct response generation |
| Customization | Limited; relies on external data | High; tailored to specific tasks |
| Scalability | Easily scales with large datasets | Resource-intensive at scale |
| Use Case Examples | Real-time Q&A, fact-checking | Sentiment analysis, domain-specific tasks |