
RAG (Retrieval-Augmented Generation) is a recent way to enhance LLMs in a highly effective way, combining generative power and real-time data retrieval. RAG allows a given AI-driven system to produce contextual outputs that are accurate, relevant, and enriched by data, thereby giving them an edge over pure LLMs.
RAG optimization is a holistic approach that consists of data tuning, model fine-tuning, and prompt engineering. This article goes through these components in depth to gain enterprise-focused insights into how these components could be the best for enterprise AI models.
Enhancing Data for Better AI Performance

- Cleansing and Organization of Data: The data must always be cleaned before proper use to remove errors, duplicates, and irrelevant sections. Take, for example, customer support AI. An AI should only reference accurate and up-to-date FAQs so that it does not reveal outdated information.
- Domain-Specific Dataset Injection: The performance is potentially improved by injecting specialized datasets developed for specific domains. A part of the achievement is injecting medical journals and patient reports (with appropriate privacy considerations) into AI in the field of healthcare to enable healthcare AI to give informed answers.
- Metadata Usage: The metadata used can include information such as timestamps, authorship, and location identifiers; doing so helps with retrieval by being right in context. For instance, an AI can see when a news article was posted and this might signal that information is more recent, and hence should come forward in the summary.
Preparing Data for RAG
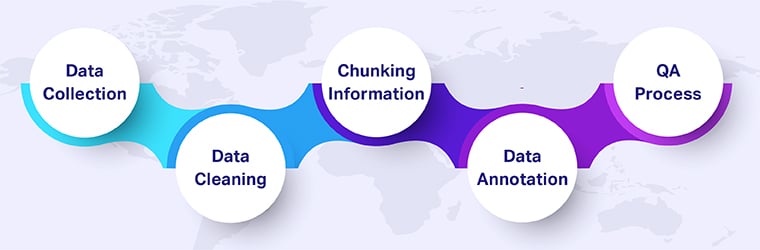
- Data Collection: By far this is the most basic step where you collect or ingest new data so that the model remains aware of current affairs. For instance, an AI wary of predicting the weather should always be collecting data and time from meteorological databases to churn out viable predictions.
- Data Cleaning: Consider the raw data coming in. It needs to first be reviewed before being further processed to remove errors, inconsistencies, or other issues. This may include activities like appropriately splitting long articles into short segments that will allow the AI to only focus on the relevant portions during context-free analysis.
- Chunking Information: Once the data has gone all through the process of cleaning, it is then going to be organized into smaller chunks so that every chunk does not exceed the limits and factors analyzed in the model training stage. Every extract must be suitably summarized in a few paragraphs or benefit from other summarization techniques.
- Data Annotation: The process of manipulation that includes labeling or identifying data adds a whole new trot to improve retrieval by informing the AI about the contextual matter. This should allow for more effective sentiment analysis of the customer feedback being manipulated into useful text applications when labeled with general emotions and feelings.
- The QA Processes: The QA processes must see through rigorous quality checks so that only quality data goes through the training and retrieval processes. This may involve double-checking manually or programmatically for consistency and accuracy.
Customizing LLMs for Specific Tasks

The personalization of LLM is an adjustment of various settings in AI to increase the model efficiency in performing certain tasks or in the spirit of facilitating certain industries. This model customization can, however, help increase the model’s capacity to recognize a pattern.
- Fine-Tuning Models: Fine-tuning is training the model on given datasets for the ability to understand the domain-specific subtleties. For example, a law firm might pick this AI model to draft contracts accurately thereafter, as it will have gone through many legal documents.
- Continuous Data Updates: You want to make sure that the model data sources are on point, and this keeps it relevant enough to become responsive to evolving topics. That is, a finance AI must regularly update its database to capture up-to-the-minute stock prices and economic reports.
- Task-Specific Adjustments: Certain models that have been fitted for certain tasks are capable of changing either or both of the features and parameters into ones that best suit that particular task. Sentiment analysis AI can be modified, for example, to recognize certain industry-specific terminologies or phrases.
Crafting Effective Prompts for RAG Models

Prompt Engineering can be understood as a way to produce the desired output using a perfectly crafted prompt. Think of it like you are programming your LLM to generate a desired output and here are some ways you can craft an effective prompt for RAG models:
- Distinctly Stated and Precise Prompts: A clearer prompt produces a better response. Rather than asking, “Tell me about technology,” it may help to ask, “What are the latest advancements in smartphone technology?”
- Iterative Advancement of Prompts: The continuous refining of a prompt based on feedback adds to its efficiency. For instance, if users find the answers too technical, the prompt can be adjusted to ask for a simpler explanation.
- Contextual Prompting Techniques: Prompting can be context-sensitive to tailor responses closer to the expectations of users. An example would be using the user preferences or previous interactions within the prompts, which produces far more personal outputs.
- Arranging Prompts in Logical Sequence: Organizing prompts in a logical sequence aids in majoring
important information. For example, when one asks about a historical event, it would be more suitable first to say, “What happened?” before he went on to ask, “Why was it significant?”
Now here’s how to get the best results from RAG systems
Regular Evaluation Pipelines: According to some evaluations, setting up an evaluation system will help RAG keep track of its quality over time, i.e., routinely reviewing how well both retrieval and generation parts of RAG perform. In short, finding out how well an AI answers questions in different scenarios.
Incorporate User Feedback Loops: The user feedback allows constant improvements to what the system has to offer. This feedback also allows the user to report things that desperately need to be addressed.






