Optical Character Recognition might sound intense and foreign to most of us, but we have been using this advanced technology more often. We use this technology quite extensively, from translating the foreign text into a language of our preference to digitizing printed paper documents. Yet, OCR technology has advanced further and has become an integral part of our tech ecosystem.
However, there is much too little information about this innovative tech, and it is time we shine the light on it.
What is Optical Character Recognition (OCR)?

A part of the Artificial Intelligence family, Optical Character Recognition is the electronic conversion of text from handwritten notes, printed text from videos, images, and scanned documents into machine-readable and digital format.
It is possible to encode text from a printed document and electronically modify, store or alter it to be stored, recovered, and used for building ML models using OCR technology.
There are two basic types of OCR – the traditional and the handwritten. Although both work towards the same result, they differ in how they extract the information.
In traditional OCR, the text is extracted based on the available font styles that the OCR systems can be trained with. On the other hand, in a handwritten OCR, where each writing style is unique, it is a challenge to read and encode. Unlike typed text, where the text appears the same across the board, handwritten text is unique to the individual. Handwritten OCR needs more training for accurate pattern recognition.
Why Is OCR Important?
As digital transformation gains a prominent stance in the world, we are witnessing the end of obsolete, legacy systems and processes. While this transition is incredible, it comes with its own set of preliminary challenges. This could be business workflows that involve backing up of print media as a way of data entry procedure.
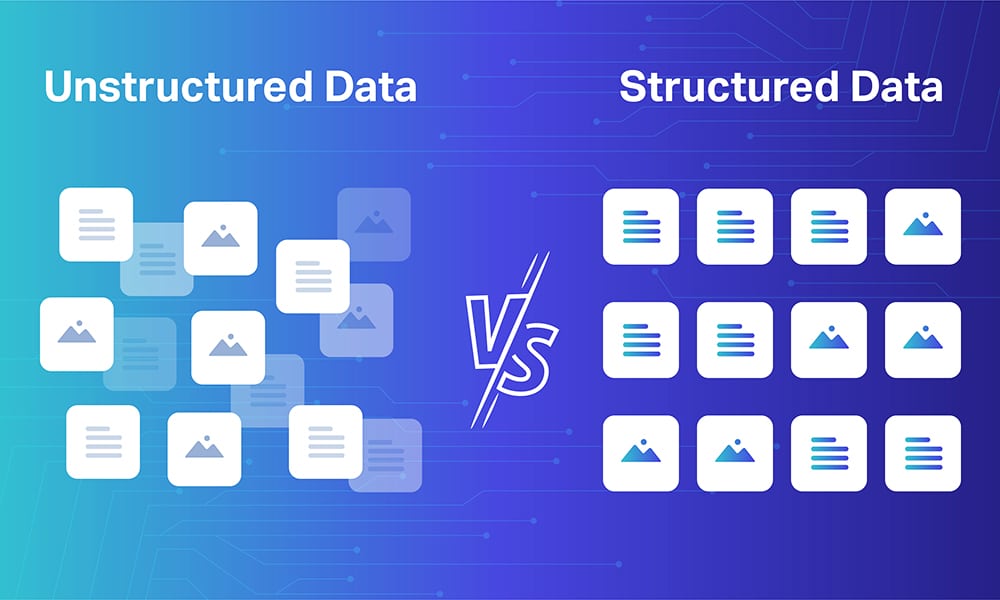
When print assets are digitized, they are often in an image format, where the text cannot be modified, manipulated or fed into AI models for training and processing. To turn them into machine-ready digital assets, they have to be identified and processed.
OCR technology takes care of this by scanning and converting text in images, videos, and other formats into data that can be fed on platforms, programming languages, and databases.
This particularly inevitable aspect in digital transformation is fueling the growth of the OCR market, where it’s estimated to grow at a CAGR of 14.32% to be valued at $40bn by 2032. Besides, with the rise of computer vision and its myriad of use cases, OCR technology has become the fulcrum around which innovations and solutions can be developed.
This could be digitizing doctors’ prescriptions in healthcare to enabling the reading of signboards in autonomous cars, OCR is the underlying technology that drives change.
How OCR Technology Works
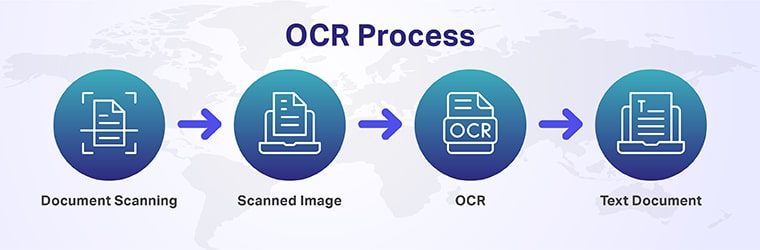
The electronic translation of offline text into digital bits is a very interesting one and meticulous. To give you a brief idea on how this works, here’s a complete breakdown:
Scanning
The first step in the process involves the use of optical scanners to scan the documents and isolate characters and data from everything else. The scanned file is stored as an image.
Refining
Since not all documents and sheets come with the same quality, all images are refined for quality optimization. This involves aligning text, smoothing out pixels, making text clearer, and more. This process makes the text readable.
Classifying
Once the image is refined, text is classified and segregated into clusters. This involves the use of image segmentation techniques to classify text into categories.
Character Recognition
With the text classified, OCR models and algorithms such as pattern and feature recognition get into action to identify text and letters. While pattern recognition looks for handwriting, fonts, text formats and other aspects, feature recognition identifies patterns like curves, line direction, lines, and more.
Post-processing
After texts are identified, output is generated, which is usually in a digital file. It’s vital to note that the results are not 100% accurate as output quality depends on paper quality, handwriting, weird text patterns, algorithms and more.
[Also Read: OCR in Healthcare: Use Cases, Benefits, and Drawbacks]

Types Of OCR
OCR does not just involve digitizing text on paper but text in any other format other than documents. Since its types and applications are diverse, the techniques and approaches deployed are distinct as well.
Intelligent Word RecognitionThis captures handwriting and cursive text, making it ideal to digitize any handwritten journal or document.
| OCR Type | What It Involves |
| Intelligent Character Recognition | This is very similar to word recognition but instead of scanning the entire text, it looks out for specific characters. |
| Optical Character Recognition | This detects typed-out text but like the name suggests, it identifies only one character at once. |
| Optical Word Recognition | Similar to character recognition, this identifies words and text instead of just characters in images with typed texts. |
| Optical Mark Recognition | Human-marked data such as OMR responses, marks on ballot sheets, tick marks in answers sheets and more are identified with this technique. |
Advantages of OCR
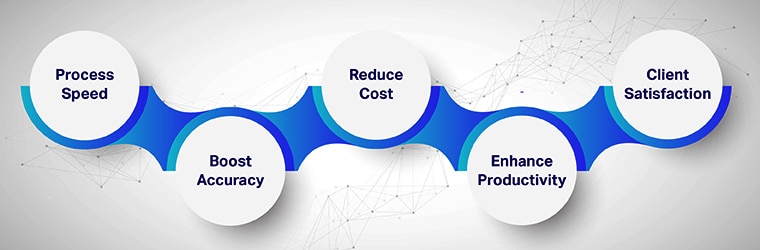
Optical Character Recognition – OCR technology – brings a range of benefits, some of which are:
Increase the speed of the process:
By quickly converting unstructured data into machine-readable and searchable information, the technology helps in increasing the speed of business processes.
Boosts accuracy:
The risk of human errors is eliminated, which improves the overall accuracy of the character recognition.
Reduces processing costs:
The Optical Character Recognition software is not entirely dependent on other technologies, reducing processing costs.
Enhances Productivity:
Since information is readily available and searchable, employees have more time to do productive tasks and achieve goals.
Improves customer satisfaction:
The availability of information in an easily searchable format ensures higher satisfaction levels and a better customer experience.
Use cases and applications
Preservation of documents / Digitization of Documents
Banking and finances
The banking and finance sector is using the OCT technology to its hilt. This technology is helping improve security fraud prevention, reduce risk, and faster processing. Banks and banking apps use OCR to extract crucial data from checks such as the account number, amount, and hand signature. OCR is helping in the faster processing of loan and mortgage applications, invoices, and payslips.
Before OCR became more common, all banking documents such as records, receipts, statements, and checks were physical. With OCR digitization, banks and financial institutions can streamline processes, eliminate manual errors, and improve process efficiency by quickly accessing data.
Number-plate recognition

OCR technology is helping implement road safety rules to avoid fraud and crimes. Since the number plates on a vehicle are linked to the driver’s credentials, identification is easier.
Moreover, the number plates consist of a well-written bunch of numbers and text that is not difficult for the AI model to read, making it easier and more accurate.
Text-to-speech
Text-to-speech application of OCR technology is an excellent help for visually-challenged people to function with greater ease. OCR technology helps in scanning physical and digital texts and using voice devices. The content is then read aloud. Although the text-to-speech aspect of OCR technology has been one of the first applications, it is now evolved and advanced to cater to the unique needs of visually challenged people by supporting several dialects and languages.
Transcription of Multi-category Scanned Paper Documents Datasets

Transcribe Medical Labels with OCR
With OCR, the healthcare industry can quickly scan, store, and search for a patient’s medical history. The OCR makes it possible to digitize and store scan reports, treatment history, hospital records, insurance records, x-rays, and other documents. By digitizing, transcribing, and storing medical labels, OCR makes it easy to streamline the process flow and speed up healthcare.
Detecting Street/Road & Extract Information Street Board data with OCR

To develop an intelligent character recognition tool, you must train it with the project-specific dataset.
At Shaip, we provide a completely customized document dataset to develop highly-functional OCR for AI and ML models. Our specialized process of OCR helps in developing optimized solutions for clients.
[Also Read: OCR Infographic – Definition, Benefits, Challenges, and Use Cases]
We provide extensive and reliable datasets that contain thousands of diverse extracted data from scanned documents. Get in touch with our OCR solutions experts to know how we provide scalable, affordable, and client-specific datasets.