
Imagine you have an x-ray report and you need to understand what injuries you have. One option is you can visit a doctor which ideally you should but for some reason, if you can’t, you can use Multimodal Large Language Models (MLLMs) which will process your x-ray scan and tell you precisely what injuries you have according to the scans.
In simple terms, MLLMs are nothing but a fusion of multiple models like text, image, voice, videos, etc. which are capable of not only processing a normal text query but can process questions in multiple forms such as images and sound.
So in this article, we will walk you through what MLLMs are, how they work and what are the top MMLMs you can use.
What are Multimodal LLMs?
Unlike traditional LLMs which can only work with one type of data—mostly text or image, these multimodal LLMs can work with multiple forms of data similar to how humans can process vision, voice, and text all at once.
At its core, multimodal AI takes in various forms of data, such as text, images, audio, video, and even sensor data, to provide a richer and more sophisticated understanding and interaction. Consider an AI system that not only views an image but can describe it, understand the context, answer questions about it, and even generate related content based on multiple input types.
Now, let’s take the same example of an x-ray report with the context of how a multimodal LLM will understand the context of it. Here’s a simple animation explaining how it first processes the image via the image encoder to convert the image into vectors and later on it uses LLM which is trained over medical data to answer the query.
Source: Google multimodal medical AI
How do Multimodal LLMs work?
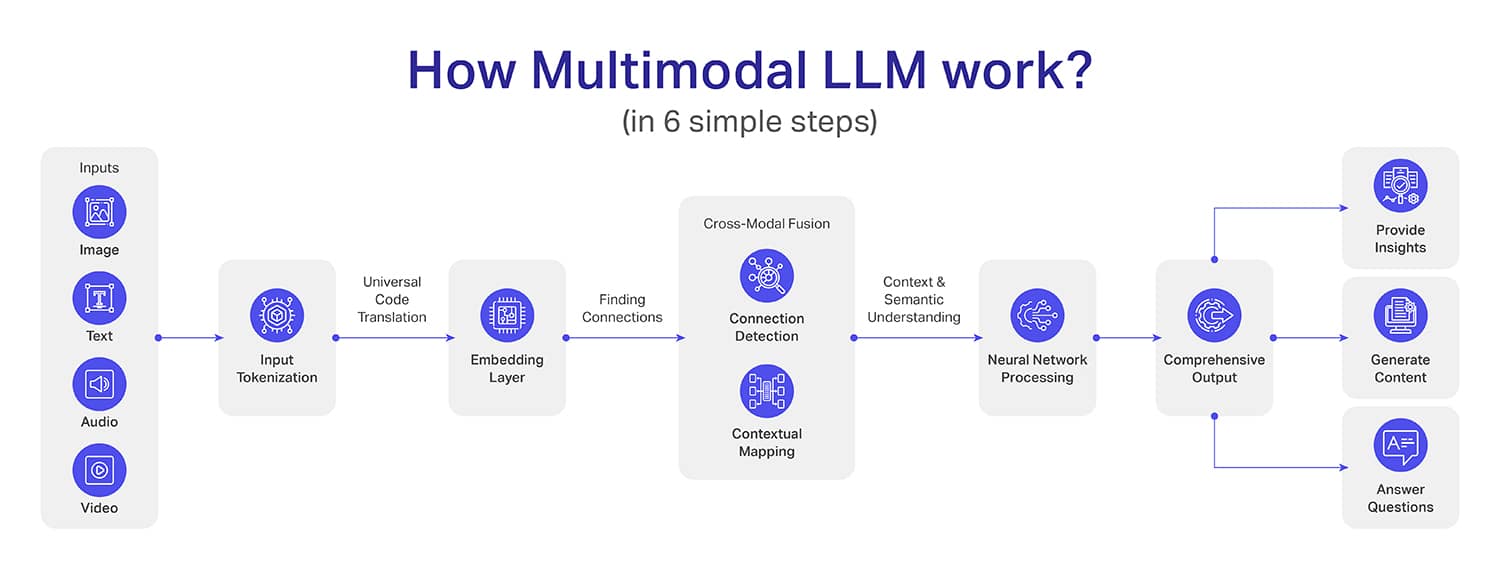
While the inner workings of multimodal LLMs are quite complex (more than LLMs), we have tried breaking them down into six simple steps:
Step 1: Input Collection – This is the first step where the data is collected and undergoes the initial processing. For example, images are converted into pixels typically using convolutional neural network (CNN) architectures.
Text inputs are converted into tokens using algorithms like BytePair Encoding (BPE) or SentencePiece. On the other hand, audio signals are converted into spectrograms or mel-frequency cepstral coefficients (MFCCs). Video data however is broken down to each frame in sequential form.
Step 2: Tokenization – The idea behind tokenization is to convert the data into a standard form so that the machine can understand the context of it. For example, to convert text into tokens, natural language processing (NLP) is used.
For image tokenization, the system uses pre-trained convolutional neural networks like ResNet or Vision Transformer (ViT) architectures. The audio signals are converted into tokens using signal processing techniques so that audio waveforms can be converted into compact and meaningful expressions.
Step 3: Embedding Layer – In this step, the tokens (which we achieved in the previous step) are converted into dense vectors in a way that these vectors can capture the context of the data. The thing to note here is each modality develops its own vectors which are cross-compatible with others.
Step 4: Cross-Modal Fusion – Till now, models were able to understand the data till the individual model level but from the 4th step, it changes. In cross-modal fusion, the system learns to connect dots between multiple modalities for deeper contextual relationships.
One good example where the image of a beach, a textual representation of a vacation on the beach, and audio clips of waves, wind, and a cheerful crowd interact. This way the multimodal LLM not only understands the inputs but also puts everything together as one single experience.
Step 5: Neural Network Processing – Neural network processing is the step where information gathered from the cross-modal fusion (previous step) gets converted into meaningful insights. Now, the model will use deep learning to analyze the intricate connections that were found during cross-modal fusion.
Image a case where you combine x-ray reports, patient notes, and symptom descriptions. With neural network processing, it will not only list facts but will create a holistic understanding that can identify potential health risks and suggest possible diagnoses.
Step 6 – Output Generation – This is the final step where the MLLM will craft a precise output for you. Unlike traditional models which are often context-limited, MLLM’s output will have a depth and a contextual understanding.
Also, the output can have more than one format such as creating a dataset, creating a visual representation of a scenario, or even an audio or video output of a specific event.
[Also Read: RAG vs. Fine-Tuning: Which One Suits Your LLM?]
What are the Applications of Multimodal Large Language Models?
Even though the MLLM is a recently tossed term, there are hundreds of applications where you will find remarkable improvements compared to traditional methods, all thanks to MLLMs. Here are some important applications of MLLM:

Healthcare and Medical Diagnostics
Multimodal LLMs can be thought of as the next medical leap in human history as compared to traditional methods which used to rely heavily on isolated data points, MLLMs can greatly improve healthcare by combining textual, visual, and audio data for more comprehensive diagnostic and treatment solutions.

Advanced Scientific Research and Discovery
In science, multimodal LLMs support breakthroughs by processing complicated data sets and revealing patterns that might go undetected otherwise.

Access and Assistive Technology
Multimodal LLMs are key in providing the development of tools for people with disabilities, access, and independence.

Creative Industries and Content Generation
Multimodal LLMs can create fresh and captivating content from mere data synthesis for the creative industries.
- Lack of MLLM Data: Finding datasets that can combine multiple formats is tough to find, especially the datasets for law and medicine.
- Complex Annotation Process: When you consider labeling datasets like videos and images, they often require expert intervention and modern tech.
- Privacy Concerns: Collecting datasets like images, videos, and text involving personal history can lead to privacy and legal complications.

How Shaip Can Help You Build Multimodal LLMs?
Shaip is well-equipped with data solutions and by providing high-quality data solutions, we ensure that your models are trained on diverse and accurate datasets, crucial for achieving optimal performance.
Whether you’re working with Large Language Models (LLMs) that require substantial computational resources or Small Language Models (SLMs) that demand efficiency, Shaip offers tailored data annotation and ethical sourcing services to meet your specific needs.






