
The internet has opened the doors to people freely expressing their opinions, views, and suggestions on just about anything in the world on social media, websites, and blogs. In addition to voicing their opinions, people (customers) are also influencing the buying decisions of others. The sentiment, whether negative or positive, is critical for any business or brand concerned about the sales of its products or services.
Helping businesses mine the comments for business use is Natural Language Processing. One in every four businesses has plans to implement NLP technology within the next year to power their business decisions. Using sentiment analysis, NLP helps businesses derive interpretable insights from raw and unstructured data.
Opinion mining or sentiment analysis is a technique of NLP used to identify the exact sentiment – positive, negative, or neutral – associated with comments and feedback. With the help of NLP, keywords in the comments are analyzed to determine the positive or negative words contained in the keyword.
Sentiments are scored on a scaling system that assigns sentiment scores to emotions in a piece of text (determining the text as positive or negative).
What is Multilingual Sentiment Analysis?

As the name suggests, multilingual sentiment analysis is the technique of performing sentiment scores for more than one language. However, it’s not as simple as that. Our culture, language, and experiences greatly influence our buying behavior and emotions. Without a good understanding of the user’s language, context, and culture, it is impossible to accurately understand user intentions, emotions, and interpretations.
While automation is the answer to many of our modern-day troubles, machine translation software will not be able to pick up the nuances of the language, colloquialisms, subtleties, and cultural references in the comments and product reviews it is translating. The ML tool might give you a translation, but it might not be useful. That’s the reason why multilingual sentiment analysis is required.
Why is Multilingual Sentiment Analysis Needed?
Most businesses use English as their communication medium, but it is not used by most consumers worldwide.
According to Ethnologue, about 13% of the world’s population speaks English. Additionally, the British Council states that about 25% of the world population has a decent understanding of English. If these numbers are to be believed, then a large portion of the consumers interact with each other and the business in a language other than English.
If the main aim of businesses is to keep their customer base intact and attract new customers, it has to intimately understand the opinions of their customers expressed in their native language. Manually reviewing each comment or translating them into English is a cumbersome process that will not yield effective results.
A sustainable solution is to develop multilingual sentiment analysis systems that detect and analyze customer opinions, emotions, and suggestions in social media, forums, surveys, and more.
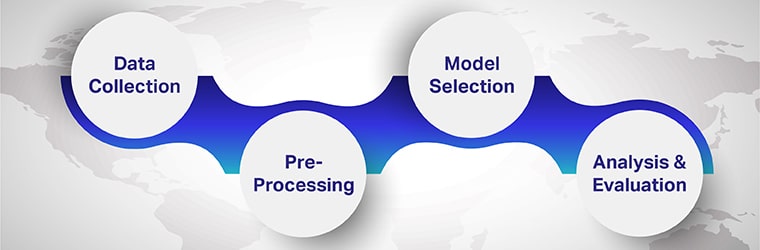
Steps to perform Multilingual Sentiment Analysis
Sentiment analysis, regardless of whether in a single language or multiple languages, is a process that requires the application of machine learning models, natural language processing, and data analysis techniques to extract multilingual sentiment scoring from the data.
The steps involved in multilingual sentiment analysis are
Step 1: Gathering Data
Gathering data is the first step in applying sentiment analysis. To create a multilingual sentiment analysis model, it is important to acquire data in a variety of languages. Everything will depend on the quality of data gathered, annotated, and labeled. You can draw data from APIs, open-source repositories, and publishers.
Step 2: Pre-processing
The web data collected should be cleaned, and information gleaned from it. The parts of the text that convey no particular meaning, such as ‘the’ ‘is’ and more, should be removed. Further, the text should be grouped into word groups to be categorized to convey a positive or negative meaning.
To improve the classification quality, the content should be cleaned of noise, such as HTML tags, advertisements, and scripts. Language, lexicon, and grammar used by people are different depending on the social network. It is important to normalize such content and prepare it for pre-processing.
Another critical step in pre-processing is using natural language processing to split sentences, remove stop words, tag parts of speech, transform words into their root form and tokenize words into symbols and text.
Step 3: Model Selection
Rule-based Model: The simplest method of multilingual semantic analysis is rule-based. The rule-based algorithm performs the analysis based on a set of predetermined rules programmed by the experts.
The rule could specify words or phrases that are positive or negative. If you take a product or service review, for example, it could contain positive or negative words such as ‘great,’ ‘slow,’ ‘wait,’ and ‘useful.’ This method makes it easy to classify words, but it could misclassify complicated or less frequent words.
Automatic Model: The automatic model performs multilingual sentiment analysis without the involvement of human moderators. Although the machine learning model is built using human effort, it can work automatically to deliver accurate results once developed.
Test data is analyzed, and each comment is manually labeled as positive or negative. The ML model will then learn from the test data by comparing the new text with the existing comments and categorizing them.
Step 4: Analysis and Evaluation
The rule-based and machine-learning models can be improved and enhanced over time and experience. A lexicon of less-frequently used words or live scores for multilingual sentiments can be updated for faster and more accurate classification.
The Challenge of Translation
Isn’t translation enough? Actually, no!
Translation involves transferring text or groups of text from one language and finding an equivalent in another. However, translation is neither simple nor effective.
That’s because humans use language not only to communicate their needs but also to express their emotions. Moreover, there are stark differences between different languages, such as English, Hindi, Mandarin, and Thai. Add to this literary mix the use of emotions, slang, idioms, sarcasm, and emojis. It is not possible to get an accurate translation of the text.
Some of the main challenges of machine translation are
- Subjectivity
- Context
- Slang and Idioms
- Sarcasm
- Comparisons
- Neutrality
- Emojis and Modern Usage of words.
Without accurately understanding the intended meaning of the reviews, comments, and communication regarding their products, prices, services, features, and quality, businesses will be unable to understand customers’ needs and opinions.
Multilingual sentiment analysis is a challenging process. Each language has its unique lexicon, syntax, morphology, and phonology. Add to this the culture, slang, sentiments expressed, sarcasm, and tonality, and you’ve got yourself a challenging puzzle that needs an efficient AI-powered ML solution.
A comprehensive multi-language dataset is needed to develop robust multilingual sentiment analysis tools that can process reviews and provide powerful insights to businesses. Shaip is the market leader in providing industry-customized, labeled, annotated datasets in several languages that aid in developing efficient and accurate multilingual sentiment analysis solutions.






