
A robust AI-based solution is built on data – not just any data but high-quality, accurately annotated data. Only the best and most refined data can power your AI project, and this data purity will have a huge impact on the project’s outcome.
We’ve often called data the fuel for AI projects, but not just any data will do. If you need rocket fuel to help your project achieve liftoff, you can’t put raw oil in the tank. Instead, data (like fuel) needs to be carefully refined to ensure that only the highest-quality information powers your project. That refinement process is called data annotation, and there exist quite a few persistent misconceptions about it.
Define Training Data Quality in Annotation
We know that data quality makes a great deal of difference to the outcome of the AI project. Some of the best and most high-performing ML models have been based on detailed and accurately labeled datasets.
But how exactly do we define quality in an annotation?
When we talk about data annotation quality, accuracy, reliability, and consistency matter. A data set is said to be accurate if it matches the ground truth and real-world information.
Consistency of data refers to the level of accuracy maintained throughout the dataset. However, the quality of a dataset is more accurately determined by the type of project, its unique requirements, and the desired outcome. Therefore, this should be the criteria for determining data labeling and annotation quality.
Why is it Important to Define Data Quality?
It is important to define data quality as it acts as a comprehensive factor that determines the quality of the project and the outcome.
- Poor quality data can impact the product and business strategies.
- A machine learning system is as good as the quality of data it is trained on.
- Good quality data eliminates rework and costs associated with it.
- It helps businesses make informed project decisions and adheres to regulatory compliance.
How do we measure Training data quality while labeling?

There are several methods to measure training data quality, and most of them start with first creating a concrete data annotation guideline. Some of the methods include:
Benchmarks established by experts
Quality benchmarks or gold standard annotation methods are the easiest and most affordable quality assurance options that serve as a reference point that measures project output quality. It measures the data annotations against the benchmark established by the experts.
Cronbach’s Alpha test
Cronbach’s alpha test determines the correlation or consistency between dataset items. The label’s reliability and greater accuracy can be measured based on the research.
Consensus Measurement
Consensus measurement determines the level of agreement between machine or human annotators. Consensus should typically be arrived at for each item and should be arbitrated upon in case of disagreements.
Panel Review
An expert panel usually determines the label’s accuracy by reviewing data labels. Sometimes, a defined portion of data labels is usually taken as a sample for determining accuracy.
Reviewing Training data Quality
The companies taking on AI projects are fully bought into the power of automation, which is why many continue to think that auto annotation-driven by AI will be faster and more accurate than annotating manually. For now, the reality is that it takes humans to identify and classify data because accuracy is so important. The additional errors created through automatic labeling will require additional iterations to improve the algorithm’s accuracy, negating any time savings.
Another misconception — and one that’s likely contributing to the adoption of auto annotation — is that small errors don’t have much of an effect on outcomes. Even the smallest errors can produce significant inaccuracies because of a phenomenon called AI drift, where inconsistencies in input data lead an algorithm in a direction that programmers never intended.
The quality of the training data – the aspects of accuracy and consistency – are consistently reviewed to meet the unique demands of the projects. A review of the training data is typically performed using two different methods –
Auto annotated techniques
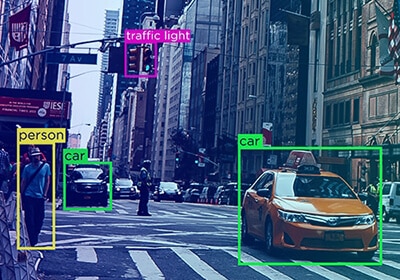
Auto annotation driven by artificial intelligence is accurate and faster. Auto annotation reduces the time manual QAs spend reviewing, allowing them to spend more time on complex and critical errors in the dataset. Auto annotation can also help detect invalid answers, repetitions, and incorrect annotation.
Manually via data science experts
Data scientists also review data annotation to ensure accuracy and reliability in the dataset.
Small errors and annotation inaccuracies can significantly impact the outcome of the project. And these errors might not be detected by the auto annotation review tools. Data scientists do sample quality testing from different batches size to detect data inconsistencies and unintended errors in the dataset.
Behind Every AI Headline Is an Annotation Process, and Shaip Can Help Make It Painless
Avoiding AI Project Pitfalls
Many organizations are plagued by a lack of in-house annotation resources. Data scientists and engineers are in high demand, and hiring enough of these professionals to take on an AI project means writing a check that is out of reach for most companies. Instead of choosing a budget option (such as crowdsourcing annotation) that will eventually come back to haunt you, consider outsourcing your annotation needs to an experienced external partner. Outsourcing ensures a high degree of accuracy while reducing the bottlenecks of hiring, training, and management that arise when you try to assemble an in-house team.
When you outsource your annotation needs with Shaip specifically, you tap into a powerful force that can accelerate your AI initiative without the shortcuts that will compromise all-important outcomes. We offer a fully managed workforce, which means you can get far greater accuracy than you would achieve through crowdsourcing annotation efforts. The upfront investment might be higher, but it will pay off during the development process when fewer iterations are necessary to achieve the desired result.
Our data services also cover the entire process, including sourcing, which is a capability that most other labeling providers can’t offer. With our experience, you can quickly and easily acquire large volumes of high-quality, geographically diverse data that’s been de-identified and is compliant with all relevant regulations. When you house this data in our cloud-based platform, you also get access to proven tools and workflows that boost the overall efficiency of your project and help you progress faster than you thought possible.
And finally, our in-house industry experts understand your unique needs. Whether you’re building a chatbot or working to apply facial-recognition technology to improve healthcare, we’ve been there and can help develop guidelines that will ensure the annotation process accomplishes the goals outlined for your project.
At Shaip, we aren’t just excited about the new era of AI. We’re helping it along in incredible ways, and our experience has helped us get countless successful projects off the ground. To see what we can do for your own implementation, reach out to us to request a demo today.






