
Artificial Intelligence fosters human-like interactions with computing systems, while Machine Learning allows these machines to learn to mimic human intelligence through every interaction. But what powers these highly-advanced ML and AI tools? Data annotation.
Data is the raw material powering ML algorithms – the more data you employ, the better the AI product will be. While it is critically important to have access to large quantities of data, it is equally important to ensure they are accurately annotated to yield feasible results. Data annotation is the data powerhouse behind advanced, reliable, and accurate ML algorithmic performance.
Role of data annotation in AI training
Data annotation plays a key role in ML training and the overall success of AI projects. It helps identify specific images, data, objectives, and videos and labels them to make it easier for the machine to identify patterns and classify data. It is a human-led task that trains the ML model to make accurate predictions.
If the data annotation is not performed accurately, the ML algorithm cannot associate attributes with objects easily.
Importance of annotated training data for AI systems
Data annotation enables the accurate functioning of ML models. There is an indisputable link between the accuracy and precision of data annotation and the success of the AI project.
The global AI market value, estimated to be $119 billion in 2022, is predicted to reach $1,597 billion by 2030, growing at a CAGR of 38% during the period. While the entire AI project goes through several critical steps, the data annotation stage is where your project is at the most significant stage.
Collecting data for data’s sake is not going to help your project much. You need massive quantities of high-quality, relevant data to implement your AI project successfully. Approximately 80% of your time in ML project development is spent on data-related tasks, such as labeling, scrubbing, aggregating, identifying, augmenting, and annotating.
Data annotation is one area where humans have an advantage over computers because we have the innate ability to decipher intent, wade through ambiguity, and classify uncertain information.
Why is Data Annotation Important?
The value and credibility of your artificial intelligence solution depend largely on the quality of data input used for model training.
A machine can’t process images as we do; they need to be trained to recognize patterns through training. Since machine learning models cater to a wide range of applications – critical solutions such as healthcare and autonomous vehicles – where any error in data annotation can have dangerous repercussions.
Data annotation ensures that your AI solution works to its full capability. Training an ML model to accurately interpret its environment through patterns and correlations, make predictions, and take necessary action requires highly categorized and annotated training data. The annotation shows the ML model the required prediction by tagging, transcribing, and labeling critical features in the dataset.
Supervised learning
Before we dig deeper into data annotation, let’s unravel data annotation through supervised and unsupervised learning.
A subcategory of machine learning supervised machine learning indicates AI model training with the help of a well-labeled dataset. In a supervised learning method, some data is already accurately tagged and annotated. The ML model, when exposed to new data, makes use of the training data to come up with an accurate prediction based on the labeled data.
For example, the ML model is trained on a cupboard full of different types of clothes. The first step in training would be to train the model with different types of clothes using the characteristics and attributes of each item of cloth. After the training, the machine will be able to identify separate pieces of clothing by applying its previous knowledge or training. Supervised learning can be categorized into classification (based on category) and regression (based on real value).
How data annotation affects the performance of AI systems
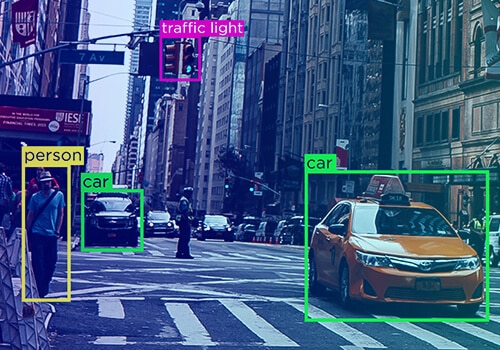
For the machine to understand and accurately identify different entities, it is important to emphasize the quality of Named Entity Tagging. One mistake in tagging and annotation, and the ML could not distinguish between Amazon – the e-commerce store, the river, or a parrot.
Besides, data annotation helps machines recognize subtle intent – a quality that comes naturally to humans. We communicate differently, and humans understand both explicitly expressed thoughts and implied messages. For example, social media replies or reviews could be both positive and negative, and the ML should be able to understand both. ‘Great place. Will visit again.’ It is a positive phrase while ‘What a great place it used to be! We used to love this place!’ is negative, and human annotation can make this process much easier.

Challenges in data annotation and how to overcome them
Two main challenges in data annotation are cost and accuracy.
The Need for Highly Accurate Data: The fate of AI and ML projects depends on the quality of annotated data. The ML and AI models must be consistently fed with well-classified data that can train the model to recognize the correlation between variables.
The Need for Large Quantities of Data: All ML and AI models thrive on large datasets – a single ML project needs at least thousands of labeled items.
The Need for Resources: AI projects are resource-dependent, both in terms of cost, time, and workforce. Without either of these, your data annotation project quality could go haywire.
[Also Read: Video Annotation for Machine Learning ]
Best Practices in Data Annotation
The value of data annotation is evident in its impact on the outcome of the AI project. If the dataset you are training your ML models on is riddled with inconsistencies, biased, unbalanced, or corrupted, your AI solution could be a failure. Additionally, if the labels are wrong and the annotation is inconsistent, then the AI solution too will bring about inaccurate predictions. So, what are the best practices in data annotation?
Tips for efficient and effective data annotation
- Make sure the data labels you create are specific and consistent with the project need and yet general enough to cater to all possible variations.
- Annotate large quantities of data necessary to train the machine learning model. The more data you annotate, the better the outcome of the model training.
- Data annotation guidelines go a long way in establishing quality standards and ensuring consistency throughout the project and across several annotators.
- Since data annotation can be costly and manpower-dependent, checking out pre-labeled datasets from service providers makes sense.
- To aid in accurate data annotation and training, bring in the efficiencies of human-in-the-loop to bring diversity and deal with critical cases along with the capabilities of annotation software.
- Prioritize quality by testing the annotators for quality compliance, accuracy, and consistency.
Importance of quality control in the annotation process

So, quality control in the image, video labeling, and annotation process plays a significant role in the AI outcome. However, maintaining high-quality control standards throughout the annotation process is challenging for small and large-scale companies. The dependence on various types of annotation tools and diverse annotation workforce can be hard to assess and maintain quality consistency.
Maintaining the quality of distributed or remote working data annotators is tough, especially for those unfamiliar with the required standards. Additionally, troubleshooting or error rectification can take time as it needs to be identified across a distributed workforce.
The solution would be training the annotators, involving a supervisor, or having multiple data annotators look into and review peers for dataset annotation accuracy. Finally, regularly testing the annotators on their knowledge of the standards.
The role of annotators and how to select the right annotators for your data
Human annotators hold the key to a successful AI project. Data annotators ensure the data is accurately, consistently, and reliably annotated since they can provide context, understand intent, and lay the foundation for ground truths in the data.
Some data is being artificially or automatically annotated with the help of automation solutions with a fair degree of reliability. For example, you can download hundreds of thousands of images of houses from Google and make them as a dataset. However, the accuracy of the dataset can only be reliably determined after the model starts its performance.
Automated automation might make matters easier and faster, but undeniably, less accurate. On the flip side, a human annotator can be slower and costlier, but they are more accurate.
Human data annotators can annotate and classify data based on their subject matter expertise, innate knowledge, and specific training. Data annotators establish accuracy, precision, and consistency.
[Also Read: A Beginner’s Guide to Data Annotation: Tips and Best Practices ]
Conclusion
To create a high-performing AI project, you need high-quality annotated training data. While acquiring well-annotated data consistently could be time, and resource-consuming – even for large corporates – the solution lies in seeking the services of established data annotation service providers like Shaip. At Shaip, we help you scale your AI capabilities through our data annotation specialist services by meeting market and customer demand.






