
Automatic speech recognition (ASR) has come a long way. Though it was invented long ago, it was hardly ever used by anyone. However, time and technology have now changed significantly. Audio transcription has substantially evolved.
Technologies such as AI (Artificial Intelligence) have powered the process of audio-to-text translation for quick and accurate results. As a result, its applications in the real world have also increased, with some popular apps like Tik Tok, Spotify, and Zoom embedding the process into their mobile apps.
So let us explore ASR and discover why it is one of the most popular technologies in 2022.
What is speech to text?
Speech to text is an AI-enhanced technology that translates human speech from an analog to a digital form. Further, the digital form of the collected data is transcripted into a text format.
Speech to text is often confused with voice recognition which is entirely different from this method. In voice recognition, the focus is on identifying the voice patterns of people, whereas, in this method, the system tries to identify the words being spoken.
Common Names of Speech to Text
This advanced speech recognition technology is also popular and referred to by the names:
- Automatic speech recognition (ASR)
- Speech recognition
- Computer speech recognition
- Audio transcription
- Screen Reading
Comprehending the Working of Automatic Speech Recognition
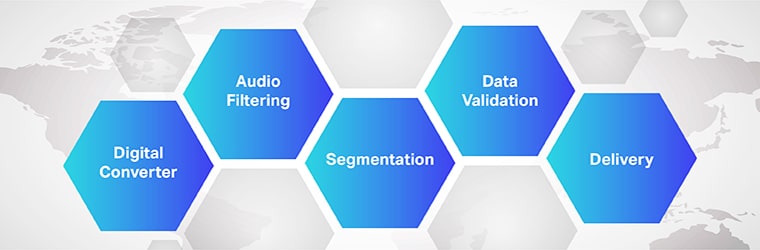
The working of audio-to-text translation software is complex and involves the implementation of multiple steps. As we know, speech-to-text is an exclusive software designed to convert audio files into an editable text format; it does it by leveraging voice recognition.
Process
- Initially, using an analog-to-digital converter, a computer program applies linguistic algorithms to the provided data to distinguish vibrations from auditory signals.
- Next, the relevant sounds are filtered by measuring the sound waves.
- Further, the sounds are distributed/segmented into hundredths or thousandths of seconds and matched against phonemes (A measurable unit of sound to differentiate one word from another).
- The phonemes are further run through a mathematical model to compare the existing data with well-known words, sentences, and phrases.
- The output is in a text or computer-based audio file.
[Also Read: A Comprehensive Overview of Automatic Speech Recognition]

What are the Uses of Speech to Text?
There are multiple automatic speech recognition software uses, such as
- Content Search: Most of us have shifted from typing letters on our phones to pressing a button for the software to recognize our voice and provide the desired results.
- Customer Service: Chatbots and AI assistants that can guide the customers through the few initial steps of the process have become common.
- Real-Time Closed Captioning: With increased global access to content, closed captioning in real-time has become a prominent and significant market, pushing ASR forward for its use.
- Electronic Documentation: Several administration departments have started using ASR to fulfill documentation purposes, catering to better speed and efficiency.
What are the Key Challenges to Speech Recognition?
Audio annotation has not yet reached the pinnacle of its development. There are still many challenges that the engineers are trying to counter to make the system efficient, such as
- Gaining control over accents and dialects.
- Understanding the context of the spoken sentences.
- Separation of background noises to amplify the input quality.
- Switching the code to different languages for efficient processing.
- Analyzing the visual cues used in the speech in the case of video files.
Audio Transcriptions and Speech-to-Text AI Development
The biggest challenge with Automatic Speech Recognition software is creating its output 100% accurately. As the raw data is dynamic and a single algorithm can not be applied, the data is annotated to train the AI to understand it in the right context.
To perform this process, specific tasks are to be implemented, such as:

- Sentiment & Topic Analysis: The software using multiple algorithms conducts the sentiment analysis of the provided data to provide error-free results.
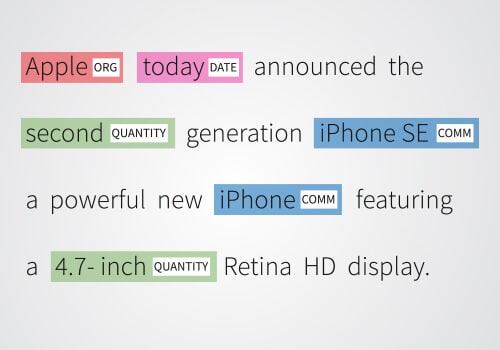
- Intent & Conversation Analysis: Intention detection aims to train the AI to recognize the speaker’s intention. It is mainly used for creating AI-powered chatbots.
Conclusion
Speech-to-text technology is at a great stage at the moment. With more digital devices incorporating voice search and control assistants into their apps, the demand for audio transcription is set to surge. If you are keen on adding this impressive feature to your app, contact Shaip’s speech data collection experts to know the full details.






