
Automatic Speech Recognition systems and virtual assistants such as Siri, Alexa, and Cortana have become common parts of our lives. Our dependence on them is significantly increasing as they get smarter. From turning on our lights to making calls to changing TV channels, we leverage these smart technologies to complete mundane tasks.
However, have you ever wondered how these speech recognition systems work?
Well, this blog will educate you on some of the fundamentals of Automatic Speech Recognition. Also, we will explore its working and how functional virtual assistants like Siri are built.
What is Automatic Speech Recognition?
Automatic Speech Recognition (ASR) is software that enables the computer system to convert human speech into text, leveraging multiple artificial intelligence and machine learning algorithms.
After converting and analyzing the given command, the computer responds with an appropriate output for the user. ASR was first introduced in 1962, and since then, it has been continually improving its operations and getting huge limelight because of popular applications like Alexa and Siri.
What is the Process for Speech Collection for Training ASR Models?
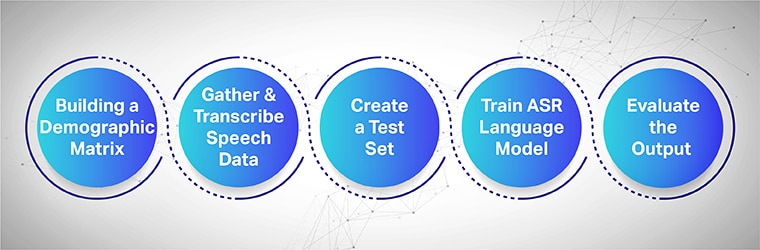
Speech collection aims to gather several sample recordings from multiple areas utilized to feed and train ASR models. ASR system delivers the highest efficiency when large datasets of speech & audio are collected and provided to its system.
To work seamlessly, the collected speech datasets must contain all target demographics, languages, accents, and dialects. The following process showcases how to train the machine learning model in multiple steps:
Start by Building a Demographic Matrix
Foremostly collects the data for different demographics such as the location, genders, language, ages, and accents. Also, ensure to capture a variety of environmental noises like street noise, waiting room noise, public office noise, etc.
Gather and Transcribe the Speech Data
The next step is collecting human audio and speech samples based on different geographical locations to train your ASR model. It is an important step and requires human experts to perform long and short utterances of words to get the genuine feel of the sentence and repeat the same sentences in different accents and dialects.
Create a Separate Test Set
Once you have gathered the transcribed text, the next step is to pair it with corresponding audio data. Then, segment the data further and include one statement from them. Now, from the segmented data pairs, you can pull random data from a set for further testing.
Train your ASR Language Model
The more information your datasets have, the better your AI-trained model would perform. Therefore, generate multiple variations of text and speeches that you recorded earlier. Paraphrase the same sentences using different speech notations.
Evaluate the Output and Finally, Iterate
Finally, measures the output of your ASR model to fix its performance. Test the model against a test set to determine its efficiency. Suitably, engage your ASR model in a feedback loop to generate the desired output and fix any gaps.
[Also Read: A Comprehensive Overview of Automatic Speech Recognition]

What are the Different Use Cases of Speech Recognition?
Speech recognition technology is highly prevalent in many industries today. Some industries using this tremendous technology are as follows:

BMW Intelligent Personal Assistant launched in its BMW 3 Series is much smarter than regular voice assistants. It can enable drivers to find car-related information and operate the car using voice commands.




[Also Read: What is Speech-To-Text Technology and How Does it Work]
How Can Shaip Help?
Shaip is one of the leading AI training services that holds expertise in multiple areas of AI and ML. They can help you with building your own data set that could be used for different applications and projects.
Some of the services provided by Shaip are:
- Automated Speech Recognition (ASR)
- Scripted Speech Collection
- Transcreation
- Spontaneous Speech collection
- Utterance Collection/ Wake-up Words,
- Text-to-speech (TTS)
You can avail of these services to get the best results for your AI-based projects. Know more about these services by reaching out to our expert team today!






