
Artificial Intelligence (AI) continues to transform industries with its speed, relevance, and accuracy. However, despite impressive capabilities, AI systems often face a critical challenge known as the AI reliability gap—the discrepancy between AI’s theoretical potential and its real-world performance. This gap manifests in unpredictable behavior, biased decisions, and errors that can have significant consequences, from misinformation in customer service to flawed medical diagnoses.
To address these challenges, Human-in-the-Loop (HITL) systems have emerged as a vital approach. HITL integrates human intuition, oversight, and expertise into AI evaluation and training, ensuring that AI models are reliable, fair, and aligned with real-world complexities. This article explores the design of effective HITL systems, their importance in closing the AI reliability gap, and best practices informed by current trends and success stories.
Understanding the AI Reliability Gap and the Role of Humans
AI systems, despite their advanced algorithms, are not infallible. Real-world examples:
| Incident | Error Type | Potential HITL Intervention |
|---|---|---|
| Canadian airline’s AI chatbot gave costly misinformation | Misinformation / Incorrect Response | Human review of chatbot responses during critical queries could catch and correct errors before they impact customers. |
| AI recruiting tool discriminated based on age | Bias / Discrimination | Regular audits and human oversight in screening decisions can identify and address biased patterns in AI recommendations. |
| ChatGPT hallucinated fictitious court cases | Fabrication / Hallucination | Human experts verifying AI-generated legal content can prevent the use of false information in critical documents. |
| COVID-19 prediction models failed to detect the virus accurately | Prediction Error / Inaccuracy | Continuous human monitoring and validation of model outputs can help recalibrate predictions and flag anomalies early. |
These incidents underscore that AI alone cannot guarantee flawless outcomes. The reliability gap arises because AI models often lack transparency, contextual understanding, and the ability to handle edge cases or ethical dilemmas without human intervention.
Humans bring critical judgment, domain knowledge, and ethical reasoning that machines currently cannot replicate fully. Incorporating human feedback throughout the AI lifecycle—from training data annotation to real-time evaluation—helps mitigate errors, reduce bias, and improve AI trustworthiness.
What Is Human-in-the-Loop (HITL) in AI?
Human-in-the-Loop refers to systems where human input is actively integrated into AI processes to guide, correct, and enhance model behavior. HITL can involve:
- Validating and refining AI-generated predictions.
- Reviewing model decisions for fairness and bias.
- Handling ambiguous or complex scenarios.
- Providing qualitative user feedback to improve usability.
This creates a continuous feedback loop where AI learns from human expertise, resulting in models that better reflect real-world needs and ethical standards.
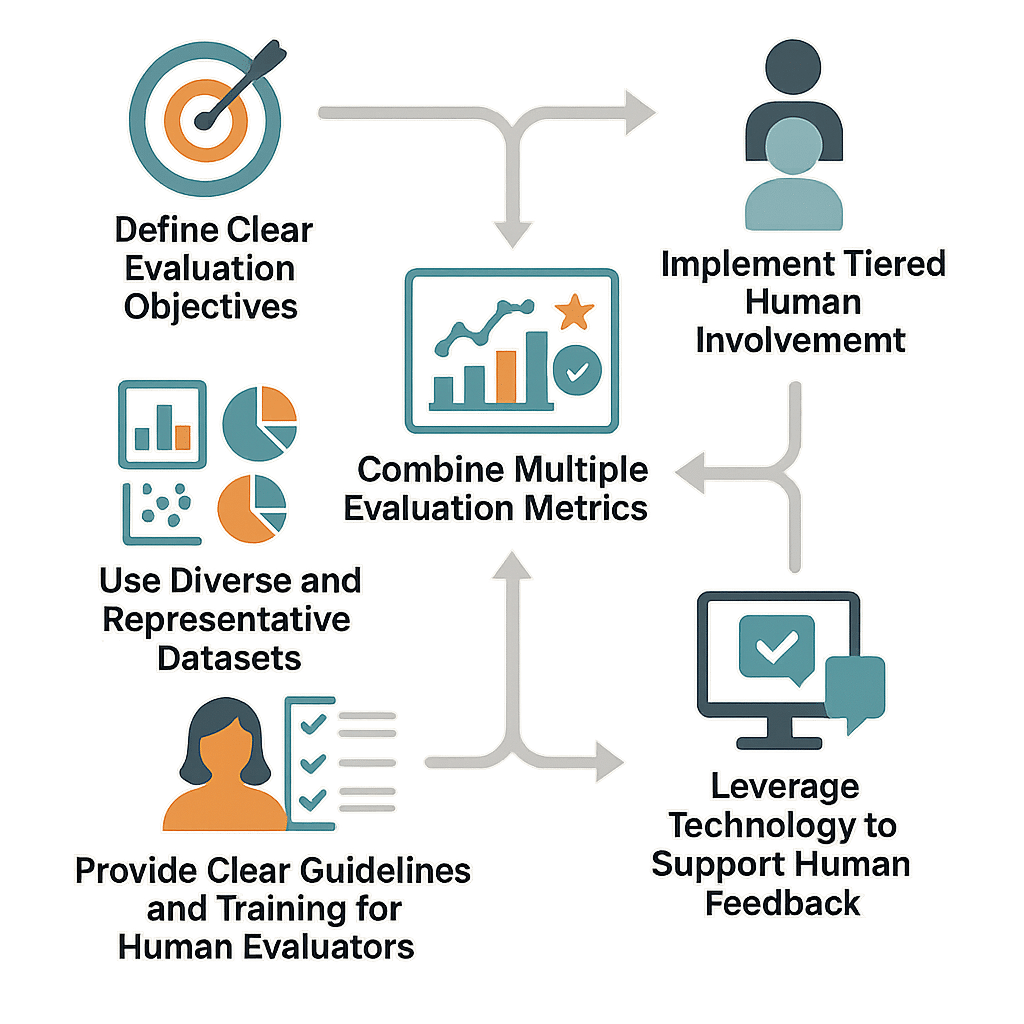
Key Strategies for Designing Effective HITL Systems
Designing a robust HITL system requires balancing automation with human oversight to maximize efficiency without sacrificing quality.

Enhancing Language Translation with Linguist Feedback
A tech company improved AI translation accuracy for less common languages by integrating native speaker feedback, capturing nuances and cultural context missed by AI alone.

Improving E-commerce Recommendations through User Input
An e-commerce platform incorporated direct customer feedback on product recommendations, enabling data analysts to refine algorithms and boost sales and engagement.

Advancing Medical Diagnostics with Dermatologist-Patient Loops
A healthcare startup used feedback from diverse dermatologists and patients to improve AI skin condition diagnosis across all skin tones, enhancing inclusivity and accuracy.

Streamlining Legal Document Analysis with Expert Review
Legal experts flagged AI misinterpretations in document analysis, helping refine the model’s understanding of complex legal language and improving research accuracy.









