Artificial intelligence (AI) improves our lives by simplifying tasks and enhancing experiences. It’s meant to complement humans, not dominate them, helping solve complex problems and drive progress.
AI is making strides in fields like healthcare, aiding in cancer research, treating neurological disorders, and speeding up vaccine development. It’s revolutionizing industries, from autonomous vehicles to smart devices and improved smartphone cameras.
The global AI market is expected to hit $267 billion by 2027, with 37% of businesses already using AI solutions. About 77% of the products and services we use today are AI-powered. How do simple devices predict heart attacks or cars drive themselves? How do chatbots seem so human?
The key is data. Data is central to AI, enabling machines to understand, process, and deliver accurate results. This guide will help you understand the importance of data in AI.
What is AI Data Collection?
One of the components of Machine Learning is the collection of data for AI. In ML processes, AI data collection is carefully gathering and organizing data to train and test AI models effectively. When carried out correctly, AI data collection guarantees that the gathered information meets the desired quality and quantity criteria.
Upon meeting these criteria, it can impact the effectiveness of AI systems and their ability to provide predictions.
Example:
A tech company is currently developing an AI-powered voice assistant designed for home devices. Here is a brief breakdown of the company’s data collection process:
They hire a specialized data collection agency like Shaip to recruit and manage thousands of participants from diverse linguistic backgrounds, ensuring a wide range of accents, dialects, and speech patterns.
The company arranges individuals to carry out activities, like setting alarms, inquiring about weather updates, managing smart home devices and responding to various commands and queries.
They record voices in environments to replicate real life situations, such, as quite rooms, busy kitchens and outdoor settings.
The company also gathers recordings of ambient noises, such as dog barks and television sounds, to assist the AI in differentiating voice commands from background noises.
They listen to each audio sample and write down information about the speaker’s characteristics as well as their emotional expressions and the level of background noise present, in each sample.
They employ methods for data augmentation to generate different versions of the audio samples, modify pitch and speed or incorporate synthetic background noise.
To protect privacy, personal information is removed from the transcripts, and audio samples are anonymized.
The company makes sure that it equally represents individuals from different age groups, different genders and accents to prevent any biases in the AI’s performance.
The company establishes a process to continuously collect data by utilizing their voice assistant in real-life scenarios. The goal is to enhance the AI’s comprehension of natural language and various query types over time. Of course, all these are done with user consent.
Common Challenges in Data Collection
Consider these factors before and during data collection:
Data Processing and Cleaning
Data processing and cleaning include removing errors or inconsistencies from the data (cleaning) and scaling numerical features to a standardized range (normalizing) to maintain accuracy and consistency. This part also involves converting the data into a format suitable for the AI model (formatting).
Labeling Data
In supervised learning, data needs to have the correct outputs or labels to it. This task can be done by human experts manually or through methods like crowdsourcing or semi-automatic techniques. The aim is to maintain consistent and high-quality labeling for optimal performance of AI models.
Privacy and Ethical Considerations
When gathering data for any purpose like research or marketing campaigns, it is necessary to align with GDPR or CCPA guidelines. It is also necessary to obtain the consent of participants and anonymize any personal information before proceeding to prevent unauthorized access or breaches of privacy standards. Additionally, ethical implications should be considered to prevent harm or discriminatory practices stemming from the collection or utilization of data in any form.
Considering Bias
Make sure that the data gathered accurately reflects different groups and situations to avoid creating biased models that could worsen societal inequalities by reinforcing or amplifying them. This step may include seeking out data points that are not well represented or maintaining a balanced dataset.
Types of AI Training Data in Machine Learning
Now, AI data collection is an umbrella term. Data in this space could mean anything. It could be text, video footage, images, audio or a mix of all of these. In short, anything that is useful for a machine to perform its task of learning and optimizing results is data. To give you more insights on the different types of data, here’s a quick list:
Datasets could be from a structured or unstructured source. For the uninitiated, structured datasets are those that have explicit meaning and format. They are easily understandable by machines. Unstructured, on the other hand, are details in datasets that are all over the place. They don’t follow a specific structure or format and require human intervention to pull out valuable insights from such datasets.
Text Data
One of the most abundant and prominent forms of data. Text data could be structured in the form of insights from databases, GPS navigation units, spreadsheets, medical devices, forms and more. Unstructured text could be surveys, handwritten documents, images of text, email responses, social media comments and more.
Audio Data
Audio datasets help companies develop better chatbots and systems, design better virtual assistants and more. They also help machines understand accents and pronunciations to the different ways a single question or query could be asked in.
Image Data
Images are another prominent dataset type that are used for diverse purposes. From self-driving cars and applications like Google Lens to facial recognition, images help systems come up with seamless solutions.
Video Data
Videos are more detailed datasets that let machines understand something in depth. Video datasets are sourced from computer vision, digital imaging and more.
How to Collect data for a Machine Learning?
This is where things start to get a little tricky. From the outset, it would appear like you have a solution to a real-world problem in mind, you know AI would be the ideal way to go about it and you’ve developed your models. But now, you are in the crucial phase where you need to commence your AI training processes. You need abundant AI training data with you to make your models learn concepts and deliver results. You also need validation data to test your results and optimize your algorithms.
So, how do you source your data? What data do you need and how much of it? What are the multiple sources to fetch relevant data?
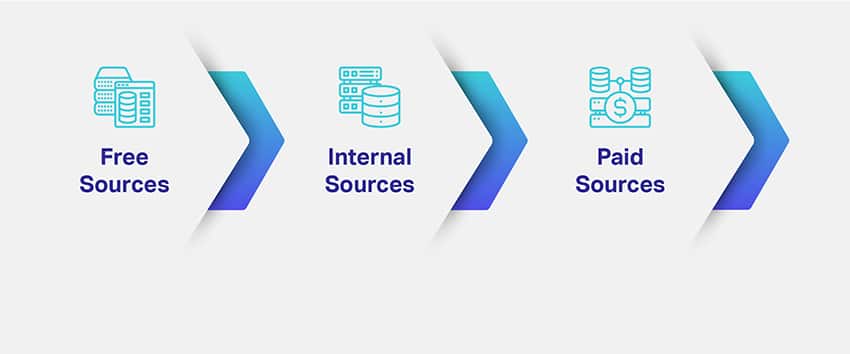
Companies assess the niche and purpose of their ML models and chart out potential ways to source relevant datasets. Defining the data type needed solves a major portion of your concern on data sourcing. To give you a better idea, there are different channels, avenues, sources or mediums for data collection:
Free Sources
Like the name suggests, these are resources that offer datasets for AI training purposes for free. Free sources could be anything ranging from public forums, search engines, databases and directories to government portals that maintain archives of information over the years.
If you don’t want to put too much effort into sourcing free datasets, there exists dedicated websites and portals like that of Kaggle, AWS resource, UCI database and more that will allow you to explore diverse categories and download required datasets for free.
Internal Resources
Though free resources appear to be convenient options, there are several limitations associated with them. Firstly, you cannot always be sure that you would find datasets that precisely match your requirements. Even if they match, datasets might be irrelevant in terms of timelines.
If your market segment is relatively new or unexplored, there wouldn’t be many categories or relevant datasets for you to download as well. To avoid the preliminary shortcomings with free resources, there exists another data resource that acts as a channel for you to generate more relevant and contextual datasets.
They are your internal sources such as CRM databases, forms, email marketing leads, product or service-defined touchpoints, user data, data from wearable devices, website data, heat maps, social media insights and more. These internal resources are defined, set up and maintained by you. So, you could be sure of its credibility, relevance and recency.
Paid Resources
No matter how useful they sound, internal resources have their fair share of complications and limitations, too. For instance, most of the focus of your talent pool will go into optimizing data touch points. Moreover, the coordination among your teams and resources must be impeccable as well.
To avoid more such hiccups like these, you have paid sources. They are services that offer you the most useful and contextual datasets for your projects & ensure you consistently get them whenever you need.
The first impression most of us have on paid sources or data vendors is that they are expensive. However, when you do the math, they are only cheap in the long run. Thanks to their expansive networks and data sourcing methodologies, you will be able to receive complex datasets for your AI projects regardless of how implausible they are.
To give you a detailed outline of the differences among the three sources, here’s an elaborate table:
Free Resources
Internal Resources
Paid Resources
Datasets are available for free.
Internal resources could also be free depending on your operational expenses.
You pay a data vendor to source relevant datasets for you.
Multiple free resources available online to download preferred datasets.
You get custom-defined data as per your needs for AI training.
You get custom-defined data consistently for as long as you require.
You need to work manually on compiling, curating, formatting and annotating datasets.
You can even modify your data touch points to generate datasets with required information.
Datasets from vendors are machine learning-ready. Meaning, they are annotated and come with quality assurance.
Stay cautious about licencing and compliance constraints on datasets you download.
Internal resources become risky if you have a limited time to market for your product.
You can define your deadlines and have datasets delivered accordingly.
How does bad data affect your AI ambitions?
We listed out the three most common data resources for the reason that you will have an idea on how to approach data collection and sourcing. However, at this point, it becomes essential to also understand that your decision could invariably decide the fate of your AI solution.
Similar to how high-quality AI training data can help your model deliver accurate and timely results, bad training data can also break your AI models, skew results, introduce bias and offer other undesirable consequences.
But why does this happen? Isn’t any data supposed to train and optimize your AI model? Honestly, no. Let’s understand this further.
Bad Data – What Is It?
Bad data is any data that is irrelevant, incorrect, incomplete or biased. Thanks to poorly-defined data collection strategies, most data scientists and annotation expertsare forced to work on bad data.
The difference between unstructured and bad data is that insights in unstructured data are all over the place. But in essence, they could be useful regardless. By spending additional time, data scientists would still be able to extract relevant information from unstructured datasets. However, that’s not the case with bad data. These datasets contain no/limited insights or information that is valuable or relevant to your AI project or its training purposes.
So, when you source your datasets from free resources or have loosely established internal data touch points, chances are highly likely that you will download or generate bad data. When your scientists work on bad data, you’re not only wasting human hours but pushing the launch of your product as well.
If you’re still unclear about what bad data can do to your ambitions, here’s a quick list:
You spend countless hours sourcing the bad data and waste hours, effort and money on resources.
Bad data could fetch you legal troubles, if unnoticed and can bring down the efficiency of your AI models.
When you take your product trained on bad data live, it affects user experience
Bad data could make results and inferences biased, which could further bring backlashes.
So, if you’re wondering if there’s a solution to this, there is actually.
AI Training Data providers to the rescue
One of the basic solutions is to go for a data vendor (paid sources). AI training data providers ensure what you receive is accurate and relevant and you have datasets delivered to you in a structured form. You don’t have to be involved in the hassles of moving from portal to portal in search of datasets.
All you have to do is take in the data and train your AI models for perfection. With that said, we’re sure your next question is on the expenses involved in collaborating with data vendors. We understand that some of you are already working on a mental budget and that’s exactly where we’re headed too next.
Factors to consider when coming up with an effective Budget for your Data Collection Project
AI training is a systematic approach and that’s why budgeting becomes an integral part of it. Factors like RoI, accuracy of results, training methodologies and more should be considered before investing a massive amount of money into AI development. A lot of project managers or business owners fumble at this stage. They make hasty decisions that bring in irreversible changes in their product development process, ultimately forcing them to spend more.
However, this section will give you the right insights. When you’re sitting down to work on the budget for AI training, three things or factors are inevitable.
Let’s look at each in detail.
The volume of data you need
We’ve been saying all along that the efficiency and accuracy of your AI model depends on how much it is trained. This means that the more the volume of datasets, the more the learning. But this is very vague. To put a number to this notion, Dimensional Research published a report that revealed that businesses need a minimum of 100,000 sample datasets to train their AI models.
By 100,000 datasets, we mean 100,000 quality and relevant datasets. These datasets should have all the essential attributes, annotations and insights required for your algorithms and machine learning models to process information and execute intended tasks.
With this is a general rule of thumb, let’s further understand that the volume of data you need also depends on another intricate factor that is your business’ use case. What you intend to do with your product or solution also decides how much data you need. For instance, a business building a recommendation engine would have different data volume requirements than a company that’s building a chatbot.
Data Pricing Strategy
When you’re done finalizing how much data you actually need, you need to next work on a data pricing strategy. This, in simple terms, means how you would be paying for the datasets you procure or generate.
In general, these are the conventional pricing strategies followed in the market:
Data Type
Pricing Strategy
Image
Priced per single image file
Video
Priced per second, minute, an hour, or individual frame
Audio / Speech
Priced per second, a minute, or hour
Text
Priced per word or sentence
But wait. This is again a rule of thumb. The actual cost of procuring datasets also depend on factors like:
The unique market segment, demographics or geography from where datasets have to be sourced
The intricacy of your use case
How much data you need?
Your time to market
Any tailored requirements and more
If you observe, you’ll know that the cost to acquire bulk quantities of images for your AI project could be less but if you have too many specifications, the prices could shoot up.
Your Sourcing Strategies
This is tricky. Like you saw, there are different ways to generate or source data for your AI models. Common sense would dictate that free resources are the best as you can download required volumes of datasets for free without any complications.
Right now, it would also appear that paid sources are too expensive. But this is where a layer of complication gets added. When you’re sourcing datasets from free resources, you are spending an additional amount of time and effort cleaning your datasets, compiling them into your business-specific format and then annotating them individually. You’re incurring operational costs in the process.
With paid sources, the payment is one-time and you also get machine-ready datasets in hand at the time you require. The cost-effectiveness is very subjective here. If you feel you could afford to spend time on annotating free datasets, you could budget accordingly. And if you believe your competition is fierce and with limited time to market, you can create a ripple effect in the market, you should prefer paid sources.
Budgeting is all about breaking down the specifics and clearly defining each fragment. These three factors should serve you as a roadmap for your AI training budgeting process in the future.
Is In-House Data Acquisition Truly Cost-Effective?
When budgeting, we found that in-house data acquisition can be more costly over time. If you’re hesitant about paid sources, this section will reveal the hidden expenses of in-house data generation.
Raw and Unstructured Data: Custom data points don’t guarantee ready-to-use datasets.
Personnel Costs: Paying employees, data scientists, and quality assurance professionals.
Tool Subscriptions and Maintenance: Costs for annotation tools, CMS, CRM, and infrastructure.
Bias and Accuracy Issues: Manual sorting required.
Attrition Costs: Recruiting and training new team members.
Ultimately, you might spend more than you gain. The total cost includes annotator fees and platform expenses, raising long-term costs.
Cost Incurred = Number of Annotators * Cost per annotator + Platform cost
If your AI training calendar is scheduled for months, imagine the expenses you would consistently incur. So, is this the ideal solution to data acquisition concerns or is there any alternative?
Benefits of an end-to-end AI Data Collection service provider
There is a reliable solution to this problem and there are better and less expensive ways to acquire training data for your AI models. We call them training data service providers or data vendors.
They are businesses like Shaip that specialize in delivering high quality datasets based on your unique needs and requirements. They take away all the hassles you face in data collection such as sourcing relevant datasets, cleaning, compiling and annotating them and more, and lets you focus only on optimizing your AI models and algorithms. By collaborating with data vendors, you focus on things that matter and on those you have control over.
Besides, you will also eliminate all the hassles associated with sourcing datasets from free and internal resources. To give you a better understanding of the advantage of an end-to-end data providers, here’s a quick list:
Training data service providers completely understand your market segment, use cases, demographics and other specifics to fetch you the most relevant data for your AI model.
They have the ability to source diverse datasets that deem fit for your project such as images, videos, text, audio files or all of these.
Data vendors clean data, structure it and tag it with attributes and insights that machines and algorithms require to learn and process. This is a manual effort that requires meticulous attention to detail and time.
You have subject matter experts taking care of annotating crucial pieces of information. For instance, if your product use case is in the healthcare space, you can’t get it annotated from a non-healthcare professional and expect accurate results. With data vendors, that’s not the case. They work with SMEs & ensure your digital imaging data is properly annotated by industry veterans.
They also take care of data de-identification and adhere to HIPAA or other industry-specific compliances and protocols so you stay away from any and all forms of legal complications.
Data vendors work tirelessly in eliminating bias from their datasets, ensuring you have objective results and inferences.
You will also receive the most recent datasets in your niche so your AI models are optimized for optimal efficiency.
They are also easy to work with. For instance, sudden changes in data requirements can be communicated to them and they would seamlessly source appropriate data based on updated needs.
With these factors, we firmly believe that you now understand how cost-effective and simple collaborating with training data providers is. With this understanding, let’s find out how you could choose the most ideal data vendor for your AI project.
Sourcing Relevant Datasets
Understand your market, use cases, demographics to source recent datasets be it images, videos, text, or audio.
Clean Relevant Data
Structure and tag the data with attributes and insights that machines and algorithms understand.
Data Bias
Eliminate bias from datasets, ensuring you have objective results and inferences.
Data Annotation
Subject matter experts from specific domains take care of annotating crucial pieces of information.
Data De-identification
Adhere to HIPAA, GDPR, or other industry-specific compliances and
protocols to eliminate legal complexities.
How to choose the right AI Data Collection Company
Choosing an AI data collection company isn’t as complicated or time-consuming as collecting data from free resources. There are only a few simple factors you need to consider and then shake hands for a collaboration.
When you’re starting to look for a data vendor, we assume that you have followed and considered whatever we’ve discussed so far. However, here’s a quick recap:
You have a well-defined use case in mind
Your market segment and data requirements are clearly established
Your budgeting is on point
And you have an idea of the volume of data you need
With these items checked off, let’s understand how can you look for an ideal training data service provider.
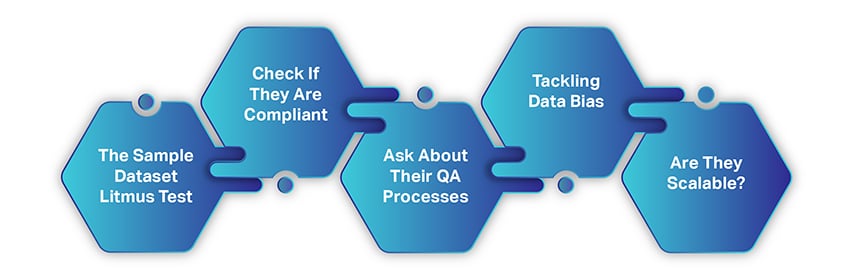
The Sample Dataset Litmus Test
Before signing a long-term deal, it’s always a good idea to understand a data vendor in detail. So, start your collaboration with a requirement of a sample dataset that you will pay for.
This could be a small volume of dataset to assess if they’ve understood your requirements, have the right procurement strategies in place, their collaboration procedures, transparency and more. Considering the fact that you would be in touch with multiple vendors at this point, this will help you save time on deciding a provider and finalize on who is ultimately better suited for your needs.
Check If They Are Compliant
By default, most training data service providers comply with all regulatory requirements and protocols. However, just to be on the safe side, enquire about their compliances and policies and then narrow down your selection.
Ask About Their QA Processes
The process of data collection by itself is systematic and layered. There is a linear methodology that is implemented. To get an idea of how they operate, ask about their QA processes and enquire whether the datasets they source and annotate are passed through quality checks and audits. This will give you an idea on whether the final deliverables you would receive are machine-ready.
Tackling Data Bias
Only an informed customer would ask about bias in training datasets. When you’re speaking to training data vendors, talk about data bias and how they manage to eliminate bias in the datasets they generate or procure. While it’s common sense that it is difficult to eliminate bias completely, you could still know the best practices they follow to keep bias at bay.
Are They Scalable?
One-time deliverables are good. Long-term deliverables are better. However, the best collaborations are those that support your business visions and simultaneously scale their deliverables with your increasing requirements.
So, discuss if the vendors you’re speaking to can scale up in terms of data volume if a need arises. And if they can, how the pricing strategy will change accordingly.
Conclusion
Do you want to know a shortcut to find the best AI training data provider? Get in touch with us. Skip all these tedious processes and work with us for the most high-quality and precise datasets for your AI models.
We check all the boxes we’ve discussed so far. Having been a pioneer in this space, we know what it takes to build and scale an AI model and how data is at the center of everything.
We also believe the Buyer’s Guide was extensive and resourceful in different ways. AI training is complicated as it is but with these suggestions and recommendations, you can make them less tedious. In the end, your product is the only element that will ultimately benefit from all this.