

What are Large Language Models?
Large Language Models (LLMs) are advanced artificial intelligence (AI) systems designed to process, understand, and generate human-like text. They’re based on deep learning techniques and trained on massive datasets, usually containing billions of words from diverse sources like websites, books, and articles. This extensive training enables LLMs to grasp the nuances of language, grammar, context, and even some aspects of general knowledge.
Some popular LLMs, like OpenAI’s GPT-3, employ a type of neural network called a transformer, which allows them to handle complex language tasks with remarkable proficiency. These models can perform a wide range of tasks, such as:
- Answering questions
- Summarizing text
- Translating languages
- Generating content
- Even engaging in interactive conversations with users
As LLMs continue to evolve, they hold great potential for enhancing and automating various applications across industries, from customer service and content creation to education and research. However, they also raise ethical and societal concerns, such as biased behavior or misuse, which need to be addressed as technology advances.

Popular Examples of Large Language Models
Here are a few prominent examples of LLMs used widely in different industry verticals:
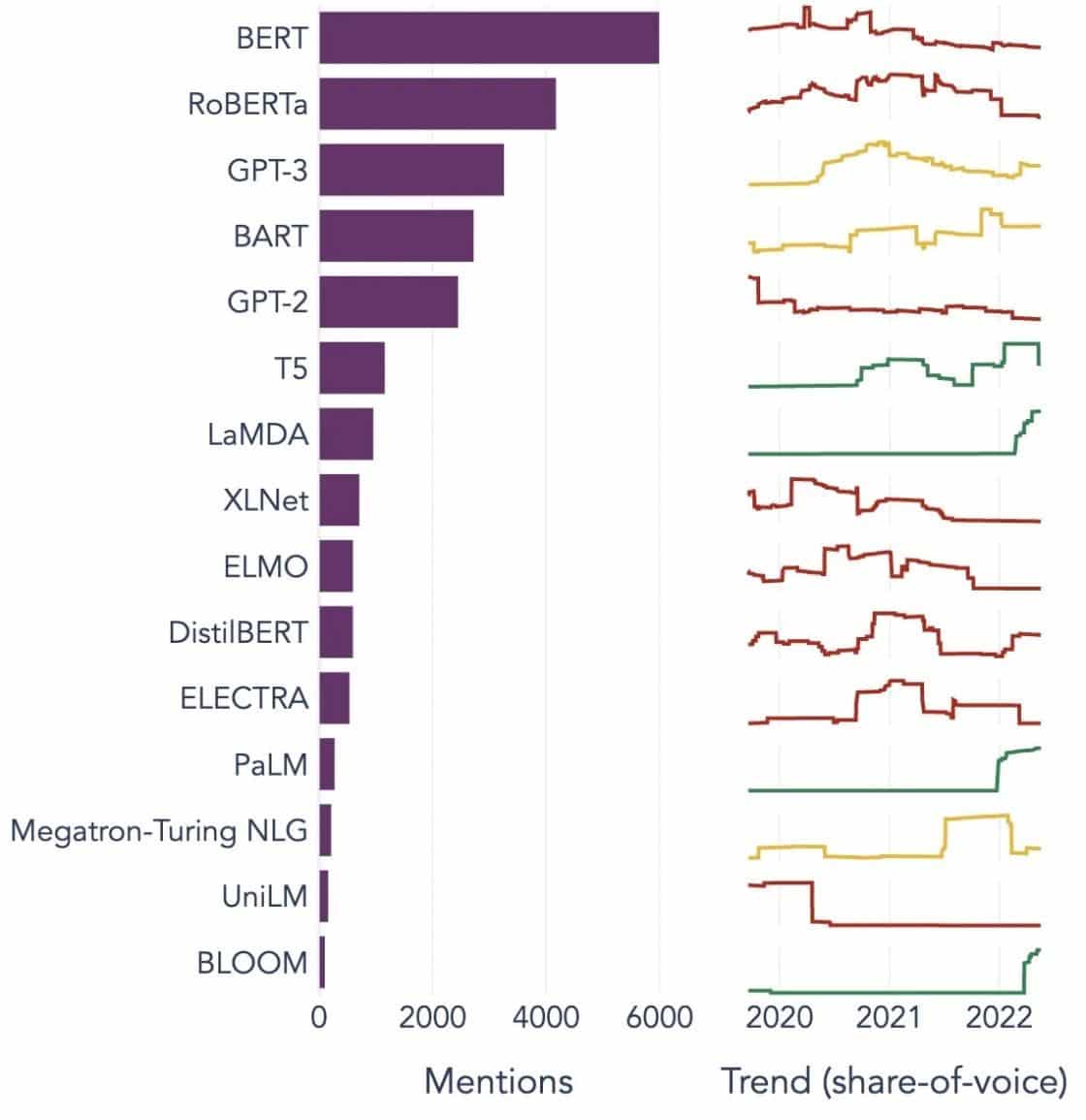
Image Source: Towards data Science
How are LLM models trained?
Training large language models (LLMs) is quite a feat that involves several crucial steps. Here’s a simplified, step-by-step rundown of the process:
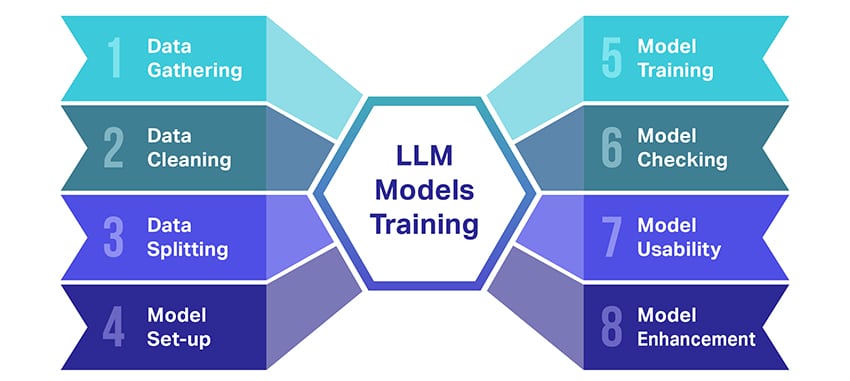
- Gathering Text Data: Training an LLM starts with the collection of a vast amount of text data. This data can come from books, websites, articles, or social media platforms. The aim is to capture the rich diversity of human language.
- Cleaning Up the Data: The raw text data is then tidied up in a process called preprocessing. This includes tasks like removing unwanted characters, breaking down the text into smaller parts called tokens, and getting it all into a format the model can work with.
- Splitting the Data: Next, the clean data is split into two sets. One set, the training data, will be used to train the model. The other set, the validation data, will be used later to test the model’s performance.
- Setting up the Model: The structure of the LLM, known as the architecture, is then defined. This involves selecting the type of neural network and deciding on various parameters, such as the number of layers and hidden units within the network.
- Training the Model: The actual training now begins. The LLM model learns by looking at the training data, making predictions based on what it has learned so far, and then adjusting its internal parameters to reduce the difference between its predictions and the actual data.
- Checking the Model: The LLM model’s learning is checked using the validation data. This helps to see how well the model is performing and to tweak the model’s settings for better performance.
- Using the Model: After training and evaluation, the LLM model is ready for use. It can now be integrated into applications or systems where it will generate text based on new inputs it’s given.
- Improving the Model: Finally, there’s always room for improvement. The LLM model can be further refined over time, using updated data or adjusting settings based on feedback and real-world usage.
Remember, this process requires significant computational resources, such as powerful processing units and large storage, as well as specialized knowledge in machine learning. That’s why it’s usually done by dedicated research organizations or companies with access to the necessary infrastructure and expertise.
Does the LLM Rely on Supervised or Unsupervised Learning?
Large language models are usually trained using a method called supervised learning. In simple terms, this means they learn from examples that show them the correct answers.

So, if you feed an LLM a sentence, it tries to predict the next word or phrase based on what it has learned from the examples. This way, it learns how to generate text that makes sense and fits the context.
That said, sometimes LLMs also use a bit of unsupervised learning. This is like letting the child explore a room full of different toys and learn about them on their own. The model looks at unlabeled data, learning patterns, and structures without being told the “right” answers.
Supervised learning employs data that’s been labeled with inputs and outputs, in contrast to unsupervised learning, which doesn’t use labeled output data.
In a nutshell, LLMs are mainly trained using supervised learning, but they can also use unsupervised learning to enhance their capabilities, such as for exploratory analysis and dimensionality reduction.
What is the Data Volume (In GB) Necessary To Train A Large Language Model?
The world of possibilities for speech data recognition and voice applications is immense, and they are being used in several industries for a plethora of applications.
Training a large language model isn’t a one-size-fits-all process, especially when it comes to the data needed. It depends on a bunch of things:
- The model design.
- What job does it need to do?
- The type of data you’re using.
- How well do you want it to perform?
That said, training LLMs usually requires a massive amount of text data. But how massive are we talking about? Well, think way beyond gigabytes (GB). We’re usually looking at terabytes (TB) or even petabytes (PB) of data.
Consider GPT-3, one of the biggest LLMs around. It is trained on 570 GB of text data. Smaller LLMs might need less – maybe 10-20 GB or even 1 GB of gigabytes – but it’s still a lot.

But it’s not just about the size of the data. Quality matters too. The data needs to be clean and varied to help the model learn effectively. And you can’t forget about other key pieces of the puzzle, like the computing power you need, the algorithms you use for training, and the hardware setup you have. All these factors play a big part in training an LLM.
The Rise of Large Language Models: Why They Matter
LLMs are no longer just a concept or an experiment. They’re increasingly playing a critical role in our digital landscape. But why is this happening? What makes these LLMs so important? Let’s delve into some key factors.
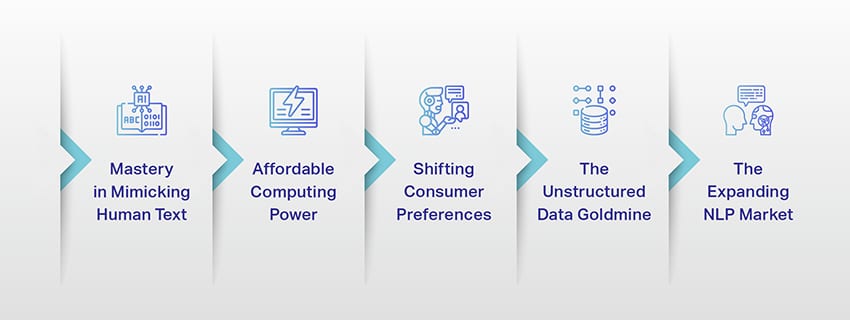
Mastery in Mimicking Human Text
LLMs have transformed the way we handle language-based tasks. Built using robust machine learning algorithms, these models are equipped with the ability to understand the nuances of human language, including context, emotion, and even sarcasm, to some extent. This capability to mimic human language isn’t a mere novelty, it has significant implications.
LLMs’ advanced text generation abilities can enhance everything from content creation to customer service interactions.
Imagine being able to ask a digital assistant a complex question and getting an answer that not only makes sense, but is also coherent, relevant, and delivered in a conversational tone. That’s what LLMs are enabling. They’re fueling a more intuitive and engaging human-machine interaction, enriching user experiences, and democratizing access to information.
Affordable Computing Power
The rise of LLMs would not have been possible without parallel developments in the field of computing. More specifically, the democratization of computational resources has played a significant role in the evolution and adoption of LLMs.
Cloud-based platforms are offering unprecedented access to high-performance computing resources. This way, even small-scale organizations and independent researchers can train sophisticated machine learning models.
Moreover, improvements in processing units (like GPUs and TPUs), combined with the rise of distributed computing, have made it feasible to train models with billions of parameters. This increased accessibility of computing power is enabling the growth and success of LLMs, leading to more innovation and applications in the field.
Shifting Consumer Preferences
Consumers today don’t just want answers; they want engaging and relatable interactions. As more people grow up using digital technology, it’s evident that the need for technology that feels more natural and human-like is increasing.LLMs offer an unmatched opportunity to meet these expectations. By generating human-like text, these models can create engaging and dynamic digital experiences, which can increase user satisfaction and loyalty. Whether it’s AI chatbots providing customer service or voice assistants providing news updates, LLMs are ushering in an era of AI that understands us better.
The Unstructured Data Goldmine
Unstructured data, such as emails, social media posts, and customer reviews, is a treasure trove of insights. It’s estimated that over 80% of enterprise data is unstructured and growing at a rate of 55% per year. This data is a goldmine for businesses if leveraged properly.
LLMs come into play here, with their ability to process and make sense of such data at scale. They can handle tasks like sentiment analysis, text classification, information extraction, and more, thereby providing valuable insights.
Whether it’s identifying trends from social media posts or gauging customer sentiment from reviews, LLMs are helping businesses navigate the large amount of unstructured data and make data-driven decisions.
The Expanding NLP Market
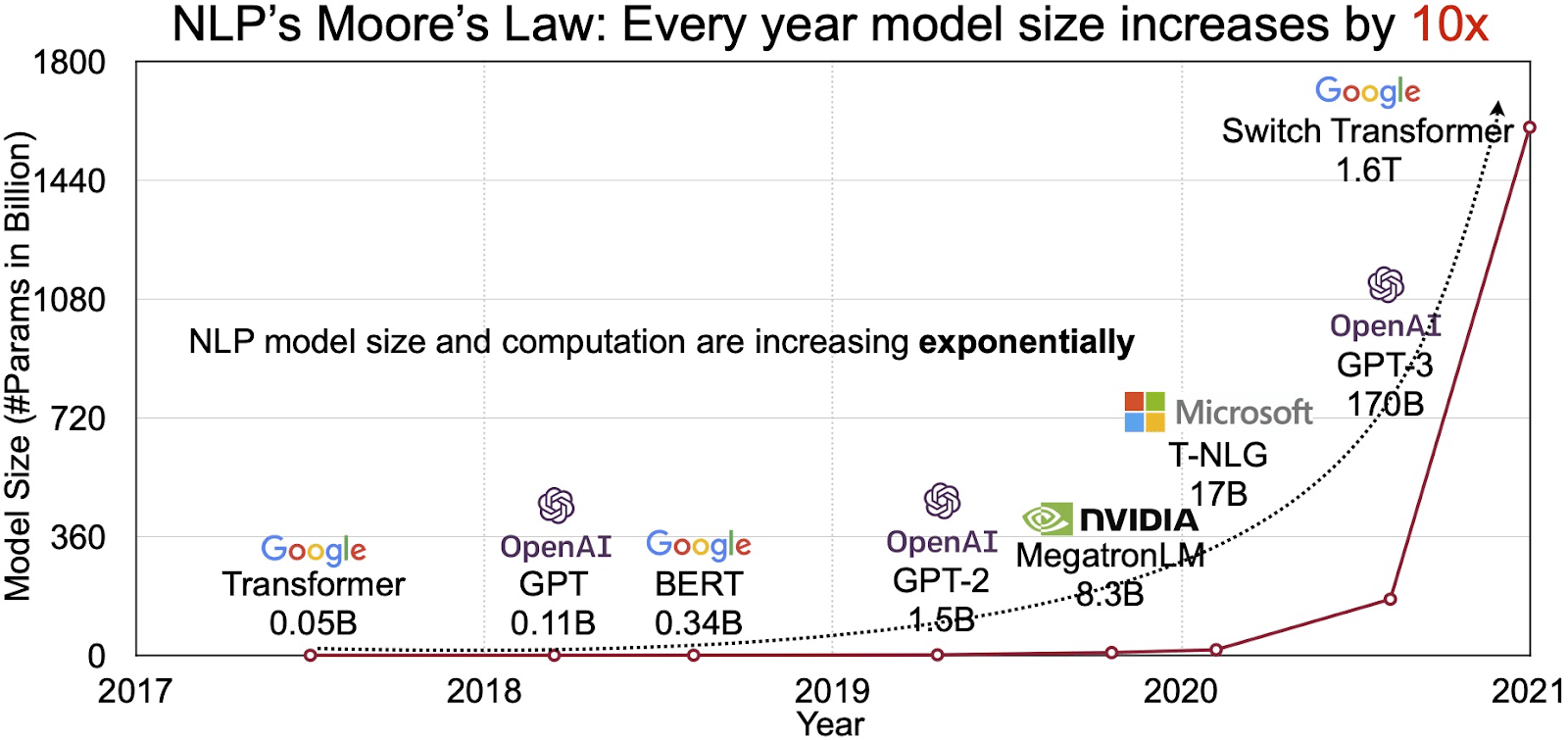
The potential of LLMs is reflected in the rapidly growing market for natural language processing (NLP). Analysts project the NLP market to expand from $11 billion in 2020 to over $35 billion by 2026. But it’s not just the market size that’s expanding. The models themselves are growing too, both in physical size and in the number of parameters they handle. The evolution of LLMs over the years, as seen in the figure below (image source: link), underscores their increasing complexity and capacity.
Popular Use Cases of Large Language Models
Here are some of the top and most prevalent use cases of LLM:
- Generating Natural Language Text: Large Language Models (LLMs) combine the power of artificial intelligence and computational linguistics to autonomously produce texts in natural language. They can cater to diverse user needs such as penning articles, crafting songs, or engaging in conversations with users.
- Translation through Machines: LLMs can be effectively employed to translate text between any pair of languages. These models exploit deep learning algorithms like recurrent neural networks to comprehend the linguistic structure of both source and target languages, thereby facilitating the translation of the source text into the desired language.
- Crafting Original Content: LLMs have opened up avenues for machines to generate cohesive and logical content. This content can be used to create blog posts, articles, and other types of content. The models tap into their profound deep-learning experience to format and structure the content in a novel and user-friendly manner.
- Analysing Sentiments: One intriguing application of Large Language Models is sentiment analysis. In this, the model is trained to recognize and categorize emotional states and sentiments present in the annotated text. The software can identify emotions such as positivity, negativity, neutrality, and other intricate sentiments. This can provide valuable insights into customer feedback and views about various products and services.
- Understanding, Summarizing, and Classifying Text: LLMs establish a viable structure for AI software to interpret the text and its context. By instructing the model to understand and scrutinize vast amounts of data, LLMs enable AI models to comprehend, summarize, and even categorize text in diverse forms and patterns.
- Answering Questions: Large Language Models equip Question Answering (QA) systems with the capability to accurately perceive and respond to a user’s natural language query. Popular examples of this use case include ChatGPT and BERT, which examine the context of a query and sift through a vast collection of texts to deliver relevant responses to user questions.

Part-of-Speech (POS) Tagging
Words in sentences are tagged with their grammatical function, such as verbs, nouns, adjectives, etc. This process assists the model in comprehending the grammar and the linkages between words.

Named Entity Recognition (NER)
Named entities like organizations, locations, and people within a sentence are marked. This exercise aids the model in interpreting the semantic meanings of words and phrases and provides more precise responses.

Sentiment Analysis
Text data is assigned sentiment labels like positive, neutral, or negative, helping the model grasp the emotional undertone of sentences. It is particularly useful in responding to queries involving emotions and opinions.
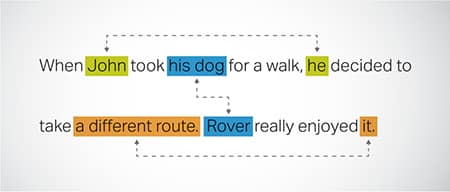
Coreference Resolution
Identifying and resolving instances where the same entity is referred to in different parts of a text. This step helps the model understand the context of the sentence, thus leading to coherent responses.
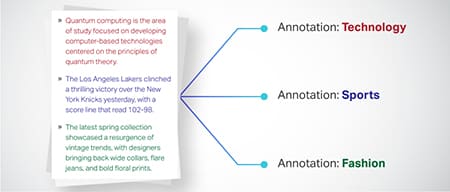
Text Classification
Text data is categorized into predefined groups like product reviews or news articles. This assists the model in discerning the genre or topic of the text, generating more pertinent responses.
Shaip’s Offering
Shaip offers a wide range of services to help organizations manage, analyze, and make the most of their data.
Data Web-Scraping
One key service offered by Shaip is data scraping. This involves the extraction of data from domain-specific URLs. By utilizing automated tools and techniques, Shaip can quickly and efficiently scrape large volumes of data from various websites, Product Manuals, Technical Documentation, Online forums, Online Reviews, Customer Service Data, Industry Regulatory Documents etc. This process can be invaluable for businesses when gathering relevant and specific data from a multitude of sources.

Machine Translation
Develop models using extensive multilingual datasets paired with corresponding transcriptions for translating text across various languages. This process helps dismantle linguistic obstacles and promotes the accessibility of information.
Taxonomy Extraction & Creation
Shaip can help with taxonomy extraction and creation. This involves classifying and categorizing data into a structured format that reflects the relationships between different data points. This can be particularly useful for businesses in organizing their data, making it more accessible and easier to analyze. For instance, in an e-commerce business, product data might be categorized based on product type, brand, price, etc., making it easier for customers to navigate the product catalog.
Data Collection
Our data collection services provide critical real-world or synthetic data necessary for training generative AI algorithms and improving the accuracy and effectiveness of your models. The data is unbiased, ethically and responsibly sourced while keeping in mind data privacy and security.

Question & Answering
Question answering (QA) is a subfield of natural language processing focused on automatically answering questions in human language. QA systems are trained on extensive text and code, enabling them to handle various types of questions, including factual, definitional, and opinion-based ones. Domain knowledge is crucial for developing QA models tailored to specific fields like customer support, healthcare, or supply chain. However, generative QA approaches allow models to generate text without domain knowledge, relying solely on context.
Our team of specialists can meticulously study comprehensive documents or manuals to generate Question-Answer pairs, facilitating the creation of Generative AI for businesses. This approach can effectively tackle user inquiries by mining pertinent information from an extensive corpus. Our certified experts ensure the production of top-quality Q&A pairs that span across diverse topics and domains.

Text Summarization
Our specialists are capable of distilling comprehensive conversations or lengthy dialogues, delivering succinct and insightful summaries from extensive text data.

Text Generation
Train models using a broad dataset of text in diverse styles, like news articles, fiction, and poetry. These models can then generate various types of content, including news pieces, blog entries, or social media posts, offering a cost-effective and time-saving solution for content creation.
Speech Recognition
Develop models capable of comprehending spoken language for various applications. This includes voice-activated assistants, dictation software, and real-time translation tools. The process involves utilizing a comprehensive dataset comprised of audio recordings of spoken language, paired with their corresponding transcripts.

Product Recommendations
Develop models using extensive datasets of customer buying histories, including labels that point out the products customers are inclined to purchase. The goal is to provide precise suggestions to customers, thereby boosting sales and enhancing customer satisfaction.
Image Captioning
Revolutionize your image interpretation process with our state-of-the-art, AI-driven Image Captioning service. We infuse vitality into pictures by producing accurate and contextually meaningful descriptions. This paves the way for innovative engagement and interaction possibilities with your visual content for your audience.

Training Text-to-Speech Services
We provide an extensive dataset comprised of human speech audio recordings, ideal for training AI models. These models are capable of generating natural and engaging voices for your applications, thus delivering a distinctive and immersive sound experience for your users.



