Data annotation or data labeling, as you know, is a perpetual process. There’s no one defining moment you could tell that you would stop training your AI modules because they’ve become perfectly accurate and swift in delivering results.
While launching your AI-powered module is just a milestone, AI training continuously happens post-launch to optimize results and efficiencies. Because of this, organizations are plagued with the concern of generating massive volumes of relevant data for their machine learning modules.
However, that’s not the concern we are going to discuss today. We are going to explore the challenges that arise once this concern of generating data is fixed. Imagine you have innumerable data generation touchpoints. The more problematic issue you will be facing at this point is annotating such huge volumes of data.
Scalable data labeling is what we are going to shed light on today because the organizations and teams we’ve spoken to have all pointed us to the fact that these stakeholders find building machine confidence more challenging than generating data. And as you know, machine confidence can be built only through properly trained systems backed by precisely annotated data. So, let’s have a look at 5 major concerns that bring down the efficiency of data labeling processes.
5 real-world challenges that dilute data labeling efforts
Workforce management

So, organizations are poised with the challenge of balancing both quality and quantity to churn out results that make a difference and solve a purpose. In such cases, managing the workforce becomes extremely difficult and strenuous. While outsourcing helps, businesses that have dedicated in-house teams for data annotation purposes, face hurdles such as:
- Employee training for data labeling
- Distribution of work across teams and fostering interoperability
- Performance and progress tracking at both micro and macro levels
- Tackling attrition and retraining new employees
- Streamlining coordination among data scientists, annotators, and project managers
- Elimination of cultural, language, and geographical barriers and removing biases from operational ecosystems and more

Tracking of finances
Budgeting is one of the most crucial phases in AI training. It defines how much you are willing to spend on building an AI module in terms of the tech stack, resources, staff, and more and then helps you calculate accurate RoI. Close to 26% of the companies that venture into developing AI systems fail halfway through because of improper budgeting. There is neither transparency on where money is being pumped into nor effective metrics that offer real-time insights to stakeholders on what their money is getting translated into.
Small and medium enterprises are often caught up in the dilemma of payment per project or per hour and in the loophole of hiring SMEs for annotation purposes vs recruiting a pool of intermediaries. All these can be eliminated during the budgeting process.
Data privacy adherence & compliance
While the number of use cases for AI is increasing, businesses are rushing to ride the wave and develop solutions that elevate life and experience. At the other end of the spectrum lies a challenge that businesses of all sizes need to pay attention to – data privacy concerns.
This pushes the need for proper maintenance of privacy standards and compliance to fair usage of confidential data. Technically, a sound and secure environment should be guaranteed by businesses that prevent unauthorized access of data, use of unauthorized devices in a data-safe ecosystem, illegal downloads of files, transfer to cloud systems, and more. Laws governing data privacy are intricate and care has to be taken to ensure every single requirement is met to avoid legal consequences.
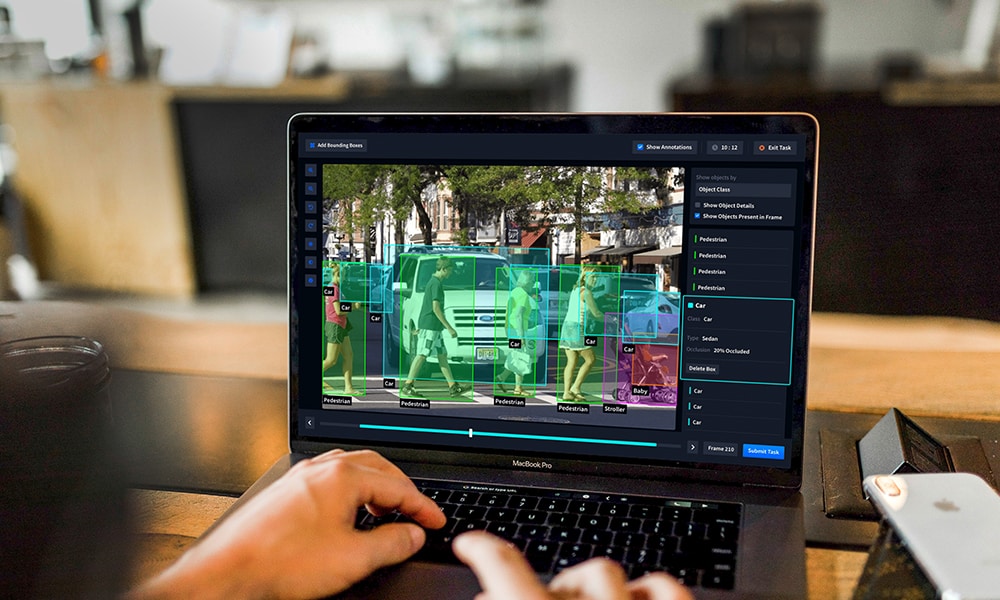
Smart tools & assisted annotations
Out of the two distinct types of annotation methods – manual and automatic, a hybrid annotation model is ideal for the future. This is because AI systems are good at processing massive amounts of data seamlessly and humans are great at pointing out errors and optimizing results.
AI-assisted tools and annotation techniques are firm solutions to the challenges we face today as it makes the lives of all stakeholders involved in the process easy. Smart tools allow businesses to automate work assignments, pipeline management, quality control of annotated data, and offer more convenience. Without smart tools, staff would be still working on obsolete techniques, pushing human hours significantly to complete work.
Managing consistency in data quality & quantity
One of the important aspects of assessing data quality is assessing the definition of labels in datasets. For the uninitiated, let’s understand that there are two major types of datasets –
- Objective data – data that is true or universal regardless of who looks at it
- And subjective data – data that could have multiple perceptions based on who accesses it
For instance, labeling an apple as a red apple is objective because it is universal but things get complicated when there are nuanced datasets in hand. Consider a witty response from a customer on a review. The annotator must be smart enough to understand if the comment is sarcastic or a compliment to label it accordingly. Sentiment analysis modules will process based on what the annotator has labeled. So, when multiple eyes and minds are involved, how does one team arrive at a consensus?
How can businesses enforce guidelines and rules that eliminate differences and bring in a significant amount of objectivity in subjective datasets?

Wrapping Up
It’s quite overwhelming, right, the amount of challenges data scientists and annotators face on a daily basis? The concerns we discussed so far are just one part of the challenge that stems from the consistent availability of data. There are lots more in this spectrum.
Hopefully, though, we will steer ahead of all this thanks to the evolution of processes and systems in data annotation. Well, there are always outsourcing (shaip) options available, that offer you high-quality data based on your requirements.